

Airbnb is one of the finest website which contains plenty of data. All these day may help organizations for their business. Thus, crawling a website like Airbnb will surely help you gain the business insight of yours and your competitors.
Airbnb is a website that allows users to rent out their places for other users to stay in for short period of time. It’s a great option if you wish to go out for a vacation and need a place to stay with your family or friends.
In this article, you will find guide or tutorial on how to crawl or scrape the Airbnb website using scrapy.
Scrapy is a web-scraping framework to crawl and scrape projects. Scrapy framework is better than other web scraping libraries, such as BeautifulSoup or Requests, for larger scraping projects.
Setting Up the Development Environment
Let’s start from the beginning. With the help of pyenv, we can easily get Python. Pyenv is a light-weight Python version management tool that helps you switch between multiple versions of Python easily.
Make sure you have Python 3.7 version as it really integrated nicely with scrapy.
1. Installing pyenv
If you have not installed pyenv, then with our instruction, you can install it now.
If you face trouble while installing, this is a useful first location to look, as pyenv has some dependencies you need before installing it.
2. Installing pyenv
Now, open up the terminal and run the following:
Next, we can set our Python version by running:
and type in 3.6.5. You can verify that you are using the correct version by running the command python -V. It should say Python 3.6.5 now.
3. Installing Scrapy
We can install scrapy by simply running:
Create Airbnb Spider
Now our environment is set up, so we can finally start a scrapy project.
Before starting it, create a folder for the project named
scrapy_tutorial.

Starting a Scrapy Project
Now create a new project by running it from your folder (e.g. cd desktop/learning/scrapy_tutorial)
It creates a project template with the name airbnb_tutorial. Now open this project in VSCode. You can use any text editor or IDE.
Now let’s create a generic spider for crawling Airbnb listings by running this command:
scrapy genspider airbnb www.airbnb.com

Now the spider has been created. It’s time to begin scraping.
Let’s Get Scraping
Here, we can do single home listing, a single page listings, or multiple listings as per our requirements. With following way, you can GET information from Airbnb for a single page.
1. Getting Our Request URL
Suppose we are looking for homes in New Jersey, USA. Our landing page looks something like this:

Follow these steps to get the request URL:
- Click right on the page and go to Inspect
- Go to the Network Tab
- Reload the Page
- Look for an entry that starts with explore_tabs?_format and click-into it
- Copy the request URL at the top
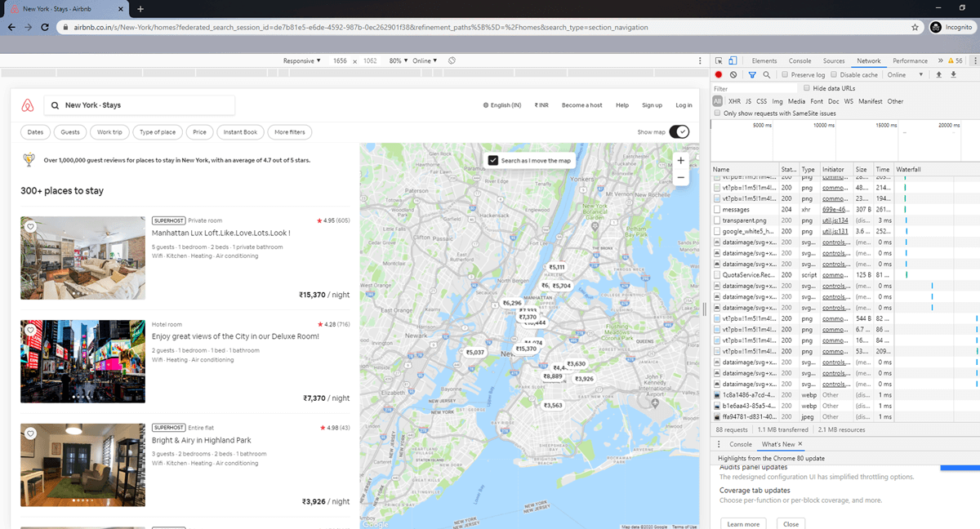
The requested URL looks something like this:
https://www.airbnb.ca/api/v2/explore_tabs?_format=for_explore_search_web&_intents=p1&auto_ib=false&client_session_id=6c7f3e7b-c038-4d92-b2b0-0bc7c25f1054¤cy=CAD&experiences_per_grid=20&fetch_filters=true&guidebooks_per_grid=20&has_zero_guest_treatment=true&is_guided_search=true&is_new_cards_experiment=true&is_standard_search=true&items_per_grid=18&key=d306zoyjsyarp7ifhu67rjxn52tv0t20&locale=en-CA&luxury_pre_launch=false&metadata_only=false&place_id=ChIJ21P2rgUrTI8Ris1fYjy3Ms4&query=Canc%C3%BAn%2C%20Mexico&query_understanding_enabled=true&refinement_paths%5B%5D=%2Fhomes&s_tag=b7cT9Z3U&satori_version=1.1.9&screen_height=948&screen_size=medium&screen_width=1105&search_type=section_navigation&selected_tab_id=home_tab&show_groupings=true&supports_for_you_v3=true&timezone_offset=-240&version=1.5.7
If JSONView is there in your system, then render the JSON object in a prettier form. It really will help you. If you scroll down, you will be able to see a JSON object that contains all the listings on our first page of listings.

2. Scraping The First Page
Now we have the request URL from the JSON object containing the first page of listings, we just have to send a scrapy request to GET it onto our systems. Now extract the fields we want with JSON file.
In your spider file (mine is airbnb.py), configure the file.
# -*- coding: utf-8 -*-
import scrapy
class AirbnbSpider(scrapy.Spider):
name = 'airbnb'
allowed_domains = ['www.airbnb.com']
start_urls = ['http://www.airbnb.com/']
def start_requests(self):
url = ('https://www.airbnb.ca/api/v2/explore_tabs?_format=for_explore_search_web'
'&_intents=p1&auto_ib=false&client_session_id=6c7f3e7b-c038-4d92-b2b0-0bc7c25f1054¤cy=CAD'
'&experiences_per_grid=20&fetch_filters=true&guidebooks_per_grid=20&has_zero_guest_treatment=true'
'&is_guided_search=true&is_new_cards_experiment=true&is_standard_search=true&items_per_grid=18'
'&key=d306zoyjsyarp7ifhu67rjxn52tv0t20&locale=en-CA&luxury_pre_launch=false&metadata_only=false'
'&place_id=ChIJ21P2rgUrTI8Ris1fYjy3Ms4&query=Canc%C3%BAn%2C%20Mexico&query_understanding_enabled=true'
'&refinement_paths%5B%5D=%2Fhomes&s_tag=b7cT9Z3U&satori_version=1.1.9&screen_height=948&screen_size=medium'
'&screen_width=1105&search_type=section_navigation&selected_tab_id=home_tab&show_groupings=true'
'&supports_for_you_v3=true&timezone_offset=-240&version=1.5.7')
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
_file = "first_page.json"
with open(_file, 'wb') as f:
f.write(response.body)
Here we have defined two functions: start_requests and parse.
start_requests send the initial scrapy request to our URL and call parse, which writes the body of the response to a JSON file called first_page.json.
Go into your project using cd command and run the spider with this simple command:
scrapy crawl {name_of_your_spider}
The name of your spider can be found in the name variable of your spider file. Here, we will pass airbnb in as the {name_of_your_spider}.
When run, it should take a few seconds to return a JSON file. Press CMD+A and then ALT+SHIFT+F to format the JSON in a more readable format.
Now we have successfully scraped the first page of listings from Airbnb.

3. Working with JSON Objects
With the help of JSON, we scraped a full page of listings. Now let’s extract the necessary information for each home. So let’s create a new Python file to test grabbing fields from the JSON file.
If you wish to grab the URL, price, number of reviews, and average rating of each home, here how you can do it.
import json
import time
import pprint
import collections
with open('first_page.json', 'r') as file:
data = json.load(file)
homes = data.get('explore_tabs')[0].get('sections')[3].get('listings')
BASE_URL = 'https://www.airbnb.com/rooms/'
data_dict = collections.defaultdict(dict)
for home in homes:
room_id = str(home.get('listing').get('id'))
data_dict[room_id]['url'] = BASE_URL + str(home.get('listing').get('id'))
data_dict[room_id]['price'] = home.get('pricing_quote').get('rate').get('amount')
data_dict[room_id]['avg_rating'] = home.get('listing').get('avg_rating')
data_dict[room_id]['reviews_count'] = home.get('listing').get('reviews_count')
printer = pprint.PrettyPrinter()
printer.pprint(data_dict)This returns the following when run:

4. Putting It All Together
Now that we have the boilerplate code to grab the specific fields we are interested in, we can put this all together in your spider file. Like so:
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import scrapy
import collections
import json
class AirbnbSpider(scrapy.Spider):
name = 'airbnb'
allowed_domains = ['www.airbnb.com']
start_urls = ['http://www.airbnb.com/']
def start_requests(self):
url = ('https://www.airbnb.ca/api/v2/explore_tabs?_format=for_explore_search_web'
'&_intents=p1&auto_ib=false&client_session_id=6c7f3e7b-c038-4d92-b2b0-0bc7c25f1054¤cy=CAD'
'&experiences_per_grid=20&fetch_filters=true&guidebooks_per_grid=20&has_zero_guest_treatment=true'
'&is_guided_search=true&is_new_cards_experiment=true&is_standard_search=true&items_per_grid=18'
'&key=d306zoyjsyarp7ifhu67rjxn52tv0t20&locale=en-CA&luxury_pre_launch=false&metadata_only=false'
'&place_id=ChIJ21P2rgUrTI8Ris1fYjy3Ms4&query=Canc%C3%BAn%2C%20Mexico&query_understanding_enabled=true'
'&refinement_paths%5B%5D=%2Fhomes&s_tag=b7cT9Z3U&satori_version=1.1.9&screen_height=948&screen_size=medium'
'&screen_width=1105&search_type=section_navigation&selected_tab_id=home_tab&show_groupings=true'
'&supports_for_you_v3=true&timezone_offset=-240&version=1.5.7')
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
data = json.loads(response.body)
homes = data.get('explore_tabs')[0].get('sections')[3].get('listings')
BASE_URL = 'https://www.airbnb.com/rooms/'
data_dict = collections.defaultdict(dict)
for home in homes:
room_id = str(home.get('listing').get('id'))
data_dict[room_id]['url'] = BASE_URL + str(home.get('listing').get('id'))
data_dict[room_id]['price'] = home.get('pricing_quote').get('rate').get('amount')
data_dict[room_id]['avg_rating'] = home.get('listing').get('avg_rating')
data_dict[room_id]['reviews_count'] = home.get('listing').get('reviews_count')
yield data_dict
To help explain parse better, we are first assigning the output of response.body (which is the contents of our first_page.json file) into data, extracting the fields in the JSON we want with the boilerplate code from json_testing.py, and finally yielding the output data_dict.
To run the spider and get output JSON file, simply run in the terminal:
cancun.json output file will be generated. It contains all the scrapped listings from the first page. Now, open the generated file and use CMD+A and then ALT+SHIFT+F to format it again.
The output will look like this:

Here you are done now. You have just scraped some listing data from Airbnb. There are many other ways you can choose: You can consider extracting the has_next_page field from the first_page.json file as a start to figuring out how to scrape multiple pages. Or, if you feel constricted with the fields in the JSON file, consider sending a scrapy request straight to the specific listing URL: https://www.airbnb.com/rooms/{room_id}
However, Splash plugin would be required, as we are now directly requesting info from Airbnb. If Airbnb uses JavaScript to render content, then scrapy on its own cannot suffice anymore.
Scraping Data from Airbnb.com isn’t easy but with professionals like X-Byte Enterprise Crawling, you can easily do that. For more information about Airbnb Data Analysis, Contact us!
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯











