

Due to the significant advancements in the advent of the NodeJS runtime, JavaScript has emerged as one of the most well-known and often-used languages. The necessary tools are now available for JavaScript, whether it’s for a web or mobile application. This blog will describe how the dynamic NodeJS environment enables you to effectively scrape the web to satisfy the majority of your requirements.
Introduction: Understanding NodeJS
JavaScript was first developed to offer dynamic functionality to webpages inside the browser. It is a straightforward and contemporary language. The JavaScript Engine of the browser runs JavaScript when a webpage is loaded and transforms it into computer-readable code.
Your browser offers a Runtime Environment that JavaScript needs in order to communicate with it (document, window, etc.).
This indicates that JavaScript is not a type of programming language that can directly communicate with or control a computer or its resources. In contrast, servers have the ability to interface directly with the computer and its resources, enabling them to read files or keep data in databases.
The main goal of NodeJS was to enable server-side Javascript execution in addition to client-side execution. Ryan Dahl, a talented developer, used Google Chrome’s v8 JavaScript Engine and integrated it with a C++ application called Node to make this happen.
Therefore, NodeJS is a runtime environment that enables the server-side execution of JavaScript-written applications.
Contrary to how other languages, including C and C++, handle concurrency, NodeJS uses a single main thread and makes use of it to carry out activities in a non-nlocking way with the use of the Event Loop.
Placing a simple web server as shown below:

If you do have NodeJS installed, you may run the code above by entering node <YourFileNameHere> (without the <and >). You will see some text stating “Hello World” after opening your browser and going to localhost:3000. I/O-intensive applications are best suited for NodeJS.
HTTP clients: Querying the Web
HTTP clients are devices that let you submit requests to servers and then get responses back from them. The majority of the tools covered in this article query the server of the website you will try to scrape using an HTTP client.
Request
One of the most popular HTTP clients in the JavaScript environment is called Request. However, the Request library’s creator currently formally announced that it is deprecated. This does not imply that it is useless. It is still utilised by many libraries and is completely worthwhile. Making an HTTP request using Request is quite easy.

Axios
A promise-based HTTP client, Axios works with both NodeJS and the browser. Axios includes built-in types for TypeScript, so you’re covered there.
With Axios, sending an HTTP request is simple. It ships by default with promise support rather than using call-backs in Request:
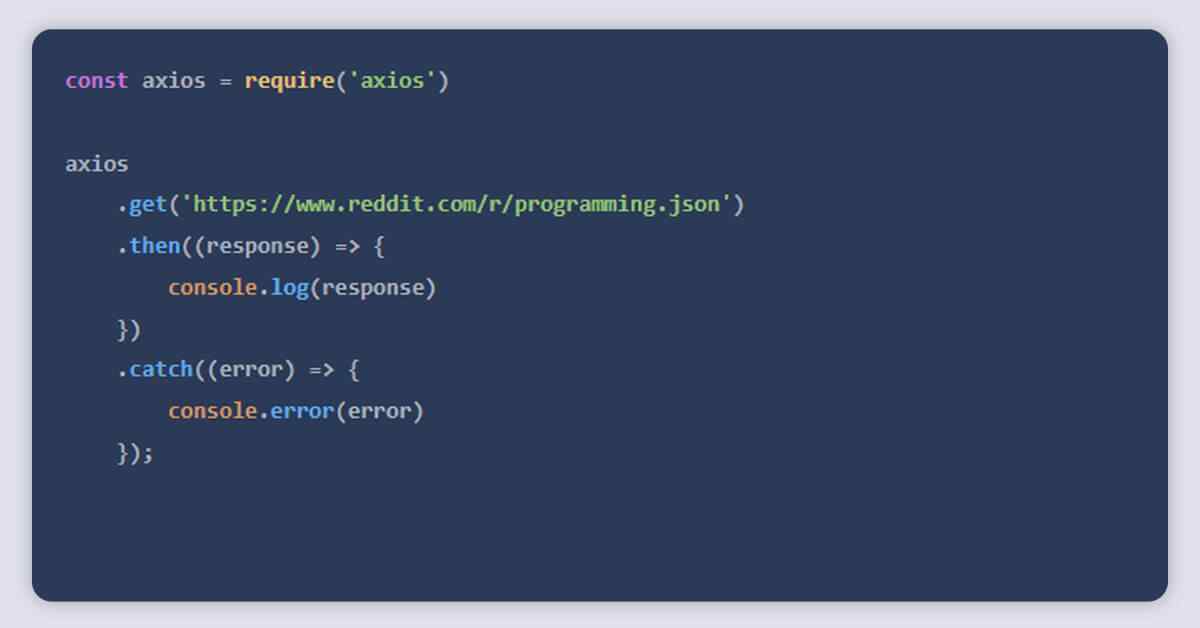
You can also use the promise API’s async/await syntactic sugar if you like. However, since top level await is still in stage 3, we must use an async function in its place:

All you can do is call getForum.
SuperAgent
SuperAgent is another capable HTTP client that supports promises and the async/await syntactic sugar, much like Axios. Like Axios, it offers a reasonably simple API, however SuperAgent is less well-known and has additional dependencies.
Regardless, utilizing promises, async/await, or callbacks, making an HTTP request with SuperAgent looks like this:

Regular Expressions: The Better Way
Using a variety of regular expressions on the HTML string that you retrieve using an HTTP client is the quickest and easiest approach to get started with web scraping without any dependencies. But there is a significant trade-off. Regular expressions are less flexible and more difficult to write appropriately for both pros and novices.
The regular expression might potentially become excessive when used for intricate web scraping. Now that that is said, let’s try it. Let’s say we want the username from a label that contains a username. Similar to what you would need to do if you used regular expressions is this:

The match () function in JavaScript typically produces an array containing every element that matches the regular expression. You may locate the textContent or innerHTML of the <label>tag, which is what we need, in the second element (in index 1). However, there is some undesirable text (“Username:”) in this result that has to be deleted.
The procedures and required labor are excessively high for such a straightforward use case. For this reason, you ought to rely on tools like an HTML parser, which we’ll cover later.
Cheerio: Core jQuery for traversing the DOM
Cheerio is a quick and effective framework that enables server-side usage of jQuery’s robust and effective API. If you have ever used jQuery, Cheerio will come naturally to you. It offers an effective API to interpret and modify the DOM while eliminating any DOM inconsistencies and browser-related functionalities.

You can see that using Cheerio is quite similar to using jQuery. However, because it functions differently from a web browser, it does not:
- Render any of the DOM elements that have been parsed or altered.
- Use CSS or a different external resource
- Implement JavaScript
Therefore, Cheerio is not your best option if the website or web application you are trying to crawl is JavaScript-heavy (for example, a Single Page Application). You might need to use the additional choices mentioned in this post later.
We’ll try to crawl the Reddit r/programming forum and compile a list of post titles to show off Cheerio’s capabilities. Install Cheerio and Axios first by executing the next command: cheerio axios npm install
Then copy/paste the following code into a new file called crawler.js:

The asynchronous method getPostTitles() will browse the archived r/programming forum on Reddit. The Axios HTTP client library is used to perform a straightforward HTTP GET request in order to first acquire the website’s HTML. After that, Cheerio is fed with the HTML data using the cheerio.load() method.
You may get a selection that can target every postcard using the aid of the browser. The $(‘div > p.title > a’) is undoubtedly familiar to you if you’ve used jQuery. This will collect every post. You must loop through each post since you just need the title of each one separately. The each () method is used to do this.
You must use Cheerio to get the DOM element in order to extract the text from each title (el refers to the current element). The text will then be returned when you call text () on each element.
Open a terminal and launch node crawler.js at this point. After that, you’ll see a list of perhaps 25 or 26 alternative post titles—it will be rather extensive. Even though this is a straightforward use case, it shows how straightforward the Cheerio API is.
The next few settings will be useful if your use case calls for the execution of JavaScript and the loading of external sources.
JSDOM: the DOM for Node
The Document Object Model is implemented in pure JavaScript by JSDOM, which may be utilized with NodeJS. Since Node does not have access to the DOM, JSDOM is the closest thing you can get. It essentially mimics the browser.
The web application or website you wish to explore may be interacted with programmatically after a DOM has been built, making actions like clicking buttons available. Using JSDOM will be simple if you are accustomed to working with the DOM.

JSDOM builds a DOM, as you can see. Then, you can control this DOM using the same tools and settings that you would use to control the DOM of a browser.
We’ll grab the very first post in the Reddit r/programming forum and upvote it to show how you may use JSDOM to interact with a website. Then, we’ll check to see if the post has received any upvotes.
Start by executing the command npm install jsdom axios to install JSDOM and Axios.
Make the following file, crawler.js, and paste the following code into it:

An asynchronous method called upvoteFirstPost() will find the very first post in the r/programming channel and vote it up. Axios performs an HTTP GET request to the provided URL to get the HTML in order to accomplish this. The HTML that was previously retrieved is then fed into a new DOM.
The HTML and the options are the first and second arguments, respectively, for the JSDOM function Object () { [native code] }. The two newly introduced choices carry out the following tasks:
RunScripts: When set to “dangerously,” it permits the execution of any JavaScript code, including event handlers. It is preferable to set runScripts to “outside-only,” which attaches all of the global supplied by the JavaScript standard to the window object and prevents any script from being performed on the inside, if you are unsure about the reliability of the scripts that your application will run.
The same DOM techniques may be used once the DOM has been generated to locate and select the upvote button from the initial post. You might look for a class named upmod in the classList to see whether it has been clicked. A message is returned if this class is present in classList.
Open a terminal and launch node crawler.js at this point. You’ll then see a neat string that will tell you if the post has been upvoted. Despite the triviality of this sample use case, you may build upon it to produce something strong (for instance, a bot that continuously upvotes a certain user’s articles).
The following choices will be a better fit if you detest JSDOM’s lack of expressiveness, your crawler substantially relies on such manipulations, or you need to recreate numerous distinct DOMs.
Introduction to Puppeteer: Headless Browser
Puppeteer, as the name suggests, enables programmatic manipulation of the browser in a manner similar to how a puppet would be controlled by its puppeteer. This is accomplished by giving developers access to a high-level API that allows them to customize Chrome to run normally or headlessly.

The advantage of puppeteer over the aforementioned solutions is that you can navigate the web as if a real person were using a browser. This creates a couple new opportunities that weren’t previously possible:
- You may create PDFs of the pages or obtain screenshots.
- A single page application can be crawled to produce material that has already been displayed.
- Numerous user activities, including keyboard inputs, form submissions, navigation, etc., may be automated.
It might also be very useful for a variety of other jobs that fall beyond the purview of web crawling, such as UI testing, performance assistance, etc.
You’ll probably wish to take screenshots of websites or learn about a competitor’s product catalog rather frequently. This can be accomplished with puppeteer. Install Puppeteer first by executing the following command: puppeteer npm install
Depending on your operating system, this will download a packaged version of Chromium that weighs anywhere about 180 to 300 MB. You must configure a few environment variables if you want to deactivate this and direct Puppeteer to a downloaded copy of Chromium.
Create a new file named crawler.js and copy/paste the following code to try to take a screenshot and PDF of the r/programming forum on Reddit:

An asynchronous function called getVisual() will create a PDF and snapshot of the value that was given to the URL variable. Puppeteer.launch is used to launch the browser in order to get things started (). A new page is then generated. You may imagine this page as a tab in a typical browser. The page that was previously constructed is then directed to the URL supplied by using page.goto() with the URL as the argument. Finally, the page and the browser instance are both deleted.
Page. Screenshot () and Page.pdf () will be used to take a screenshot and a PDF when that is complete and the page has loaded completely. These activities might also be carried out by listening to the JavaScript load event, which is strongly advised at the production stage.
You will see two files with the names screenshot.jpg and page.pdf produced when you run the code by typing node crawler.js into the console.
Additionally, we’ve prepared a thorough tutorial on using Puppeteer to download files. You ought to look into it!
Another typical use case is submitting a form using Puppeteer to do a complicated search with filters on data that is accessible only after logging in.
Alternative to Puppeteer: Nightmare
Similar to Puppeteer, Nightmare is a high-level browser automation framework. Although it uses Electron, it is believed to be more contemporary and about twice as fast as PhantomJS.
Nightmare is a great option if you don’t like Puppeteer or are put off by the size of the Chromium package. Start by executing the following command to install the Nightmare library: nightmare installing npm

A Nightmare instance is first made. Once it has loaded, this instance is then sent to the Google search engine by executing goto(). Its selection is used to retrieve the search box. The search box’s value (an input tag) is then modified to “X-Byte Enterprise Crawling”
Once this is complete, use the “Google Search” button to submit the search form. Nightmare is then instructed to hold off until the first link has loaded. A DOM technique will be used to retrieve the value of the href property of the anchor element that houses the link after it has loaded.
Finally, the URL is printed to the console after everything is finished. Type node crawler.js into your terminal to launch the program.
Conclusion
- NodeJS is a JavaScript runtime that enables server-side execution of JavaScript. The Event Loop ensures that it is non-blocking.
- To submit HTTP requests to a server and obtain a response, HTTP clients like Axios, SuperAgent, Node fetch, and Request are used.
- Cheerio does not run JavaScript code; instead, it abstracts the greatest parts of jQuery in order to run them server-side for web crawling.
- JSDOM converts an HTML string into a DOM that adheres to the Javascript specification and lets you manipulate that DOM.
- High-level browser automation frameworks like Puppeteer and Nightmare let you programmatically control online apps as though a real human were interacting with them.
For any web scraping services, contact X-Byte Enterprise Crawling today!
Request for a quote!
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯











