

Understanding the Website Structure
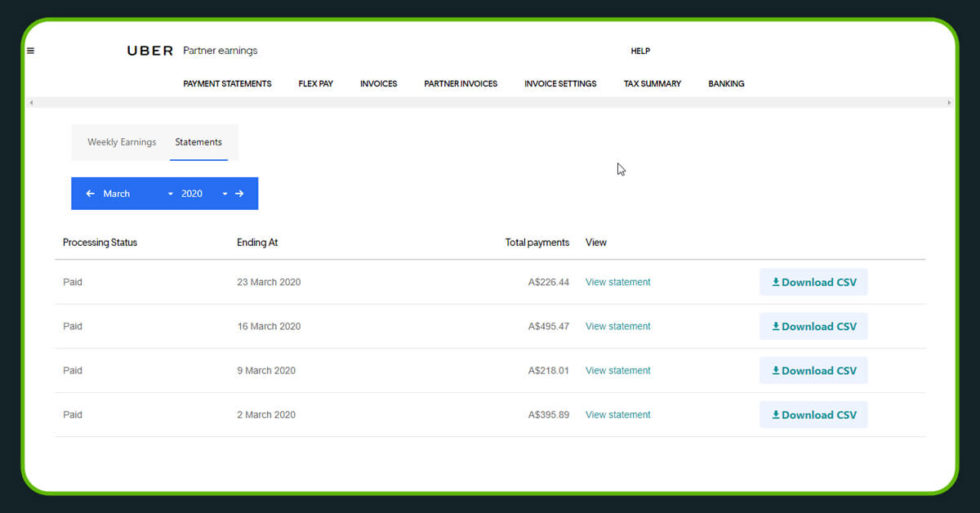
By signing into an Uber account, we can search for two pages that will provide us trip information. It is possible to find statements for every week of any month.
Now, if we download the statements, we can download CSV files that will possess unique trip ids for all the trips.
It is also possible to scrape the data from other weblinks: https://drivers.uber.com/p3/fleet-manager/trips. If we click on a particular trip

This page, as can be seen, has precise pick-up and drop-off locations, but the cost, surge, and total received is absent. For this blog, we’ll refer to this data scraping technique as “Uber Fleet Manager Scrapper.”
The plan is to extract information from both resources and then integrate it using duration and distance values that are similar. This will be discussed in more detail in the future blog.
Executing Selenium for Google Chrome
We must now configure Selenium for Google Chrome. The first step is to download Chrome Installer and save it somewhere safe. This link will take us to a page where we may get the appropriate Chrome Driver. We’ll use the code to install Selenium because we’re utilizing Jupyter Notebook and the Anaconda package management.
conda install -c conda-forge seleniumAfter that, we’ll utilize Selenium to launch Google Chrome. The following snippet can assist us in doing so.
from selenium import webdriver
browser = webdriver.Chrome('path-to-chromedriver')
browser.get('http://www.google.com/');This code should introduce a new Google Chrome window with google.com loaded. We are now ready to begin our scrapping activities. Please do not exit the Google Chrome window.
Scrapping Uber Trip Information
We need to download reports for all of the weeks we want to extract site surveys from before we can start scraping. To download all of the statements, click the link. Place most of the file system into a new folder called “Statements” once it’s finished.
You can now open a trip page using any trip ID using the below given link: https://drivers.uber.com/p3/payments/trips/{your_trip_id}.
However, the uber website requires us to check in before we can proceed. Use the steps below to log in.
import time
browser.get('https://drivers.uber.com/p3/payments/{your_trip_id}')
time.sleep(5)username = browser.find_element_by_id('useridInput')
username.send_keys('Enter-your-email-here')
Next = browser.find_element_by_class_name('push-small--right')
Next.click()
time.sleep(5)password = browser.find_element_by_id('password')
password.send_keys('Enter-your-password-here')
Next = browser.find_element_by_class_name('push-small--right')
Next.click()For further verification, you can use the below mentioned code:
verification = browser.find_element_by_id('verificationCode')
verification.send_keys('Enter code here')
Next = browser.find_element_by_class_name('push-small--right')
Next.click()We’ve now completed our registration process, and the trip id webpage should now be displayed.
Now we must develop the code that will collect information from all the trips. Our code must be written in the following order.
- First, we must put all the statements for all of the weeks in a folder called “Statements.”
- The script must then isolate the column Trip ID across all csv files and build a link for each visit.
- Finally, the script must access the website address, scrape information from it, and save the information.
The code below can be used to accomplish all of the above tasks:
import pandas as pd
import os
import time
from bs4 import BeautifulSoup
import ospath = 'Put-path-to-statements-folder-here'
files = os.listdir(path)for x in range(0,len(files)):
# Excessing files within relevant folder
f_path = os.path.join(path, files[x])
# Uploding the uber statement file and segragaing the tripID column
statement = pd.read_csv(f_path)
tripID = statement['Trip ID']# Scrapping all the relevant trip data
for tid in tripID:
# creating weblink to fetch information and pushing it onto chrome
weblink = os.path.join('https://drivers.uber.com/p3/payments/trips/',tid)
#delaying execution
time.sleep(1)
browser.get(weblink)# scrapping the page using beautiful soap
page_source = browser.page_source
soup = BeautifulSoup(page_source, 'html.parser')
pay = soup.find('h1', class_='bi br').get_text()
date = soup.find('div', class_='cs ct cu cv cw cx cy').get_text()
duration = soup.find_all('h4', class_='bi')[0].get_text()
distance = soup.find_all('h4', class_='bi')[1].get_text()
fare = soup.find_all('span', class_='c0 c1 d9 bj')[0].get_text()
pickup = soup.find_all('div', class_="dr")[0].get_text()
loc = soup.find_all('div', class_="dq")[0].get_text()
dropoff = loc.replace(pickup,"")
tripid = tid
try:
UberFee = soup.find_all('span', class_='c0 c1 d9')[1].get_text()
surge = soup.find_all('span', class_='c0 c1 d9')[0].get_text()
surge_fee = "Yes"
except:
UberFee = soup.find_all('span', class_='c0 c1 d9')[0].get_text()
surge = "NA"
surge_fee = "No"# appending results to arrays
pay_df.append(pay)
date_df.append(date)
duration_df.append(duration)
distance_df.append(distance)
fare_df.append(fare)
surge_df.append(surge)
UberFee_df.append(UberFee)
pickup_df.append(pickup)
dropoff_df.append(dropoff)
tripid_df.append(tripid)
surge_fee_df.append(surge_fee)# Enquiring Status
print("The file no " + str(x+1) + " named as " + files[x] + " is completed out of " + str(len(files)))
browser.quit()
def parse_search_page(response):
"""parsed results from TripAdvisor search page"""
sel = Selector(text=response.text)
parsed = []
# we go through each result box and extract id, url and name:
for result_box in sel.css("div.listing_title>a"):
parsed.append(
{
"id": result_box.xpath("@id").get("").split("_")[-1],
"url": result_box.xpath("@href").get(""),
"name": result_box.xpath("text()").get("").split(". ")[-1],
}
)
return parsed
async def scrape_search(query:str, session:httpx.AsyncClient):
"""Scrape all search results of a search query"""
# scrape first page
log.info(f"{query}: scraping first search results page")
hotel_search_url = 'https://www.tripadvisor.com/' + (await search_location(query, session))['HOTELS_URL']
log.info(f"found hotel search url: {hotel_search_url}")
first_page = await session.get(hotel_search_url)
# extract paging meta information from the first page: How many pages there are?
sel = Selector(text=first_page.text)
total_results = int(sel.xpath("//div[@data-main-list-match-count]/@data-main-list-match-count").get())
next_page_url = sel.css('a[data-page-number="2"]::attr(href)').get()
page_size = int(sel.css('a[data-page-number="2"]::attr(data-offset)').get())
total_pages = int(math.ceil(total_results / page_size))
# scrape remaining pages concurrently
log.info(f"{query}: found total {total_results} results, {page_size} results per page ({total_pages} pages)")
other_page_urls = [
# note "oa" stands for "offset anchors"
urljoin(str(first_page.url), next_page_url.replace(f"oa{page_size}", f"oa{page_size * i}"))
for i in range(1, total_pages)
]
# we use assert to ensure that we don't accidentally produce duplicates which means something went wrong
assert len(set(other_page_urls)) == len(other_page_urls)
other_pages = await asyncio.gather(*[session.get(url) for url in other_page_urls])
# parse all data and return listing preview results
results = []
for response in [first_page, *other_pages]:
results.extend(parse_search_page(response))
return resultsThe following link will take you to a full Jupyter notebook implementation: Uber Trip Scraper is a programe that extracts data from Uber trips. You should have a scraped dataset that looks like this.

Extracting Uber Fleet Manager Information
- We can open the website by clicking the link to extract information from Fleet Manager. The following functions must be performed by our code:
- To expand the tables, click on all of the trips.
- Fetch all of the information.
- Apply the code to all the pages in a given week.
However, there is a significant amount of manual labor required. We need to go to a specific week manually. After that, we can begin the scrapping procedure. The following code can be used to do all of the required tasks.
# Make necessary imports
from bs4 import BeautifulSoup
import time# Detect the number of pages in the week
soup = BeautifulSoup(browser.page_source, 'html.parser')
num_pages = soup.find_all("nav", role="navigation")[0].get_text().split('Previous')[1].split('Next')[0][-1]
print("This week has a total of " + str(num_pages) + " pages.")
loop = int(num_pages) + 2# Run the loop for reaching all of the pages
for x in range(2,loop):
regixNP = "//nav[@role='navigation']/ul/li[" + str(x) + "]"
browser.find_element_by_xpath(regixNP).click()
time.sleep(4)
new_soup = BeautifulSoup(browser.page_source, 'html.parser')
rows = new_soup.find_all("tr", class_="cursor--pointer _style_2T0IvR")
disp0 = "Page " + str(x-1) + " has " + str(len(rows)) + " rows."
print(disp0)
n=1# Run the loop to open all the rows to open all the data
for y in range(1,len(rows)*2,2):
regixR = "//table[1]/tbody/tr[" + str(y) + "]/td/i"
browser.find_element_by_xpath(regixR).click()
disp1 = "For page " + str(x-1) + " processing row " + str(n) + "/" + str(len(rows))
print(disp1)
n+=1
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
soup = BeautifulSoup(browser.page_source, 'html.parser')
print("Scrapping operation started.")
# Run a loop to scrap all data
for z in range(0,len(rows)*2):
# Scrap all the data and write a condition for even and odd ranges
if z%2 == 0:
ss = soup.select("tbody[data-reactid*='366'] tr")[z].get_text()
datetime = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[0]
driver = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[0]
car = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[-1].split(' Fare: ')[0]
fare = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[-1].split(' Fare: ')[-1].split(' Time: ')[0]
dur = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[-1].split(' Fare: ')[-1].split(' Time: ')[-1].split(' Kilometers: ')[0]
dis = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[-1].split(' Fare: ')[-1].split(' Time: ')[-1].split(' Kilometers: ')[-1].split(' Status: ')[0]
status = ss.split(' Requested: ')[1].split(' AESTDriver:\xa0')[1].split(' License: ')[-1].split(' Fare: ')[-1].split(' Time: ')[-1].split(' Kilometers: ')[-1].split(' Status: ')[-1]
timeseriesPD.append(datetime)
farePD.append(fare)
durPD.append(dur)
disPD.append(dis)
statusPD.append(status)
elif z%2 == 1:
tt = soup.select("tbody[data-reactid*='366'] tr")[z].get_text()
timeordered = tt.split('\n\n\n\n\n\n DELIVERY\n \n\n\n\n\n\n\n\n ')[-1].split(' AEST\n \n\n ')[0]
shop = tt.split('\n\n\n\n\n\n DELIVERY\n \n\n\n\n\n\n\n\n ')[-1].split(' AEST\n \n\n ')[1].split('\n \n\n\n\n\n\n\n\n\n\n ')[0]
timepicked = tt.split('\n\n\n\n\n\n DELIVERY\n \n\n\n\n\n\n\n\n ')[-1].split(' AEST\n \n\n ')[1].split('\n \n\n\n\n\n\n\n\n\n\n ')[-1]
timedelivered = tt.split('\n\n\n\n\n\n DELIVERY\n \n\n\n\n\n\n\n\n ')[-1].split(' AEST\n \n\n ')[2].split('\n \n\n\n\n\n\n\n\n\n\n ')[-1]
droploc = tt.split('\n\n\n\n\n\n DELIVERY\n \n\n\n\n\n\n\n\n ')[-1].split(' AEST\n \n\n ')[-1].split('\n \n\n\n\n')[0]
orderedPD.append(timeordered)
shopPD.append(shop)
pickedPD.append(timepicked)
deliveredPD.append(timedelivered)
droplocPD.append(droploc)
else:
print("Error.")
print("Page " + str(x-1) + " scrapping Complete.")We are always interested to deliver the quality data scraped content. If you feel any queries, feel free to contact us.
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯











