

The Challenge
To get hotel and flight prices, we extract Google Flights as well as Google Hotels. The hotels are comparatively simple: to get the cheapest hotels at 100 destinations with more than 5 various dates each, we need to extract 500 pages of Google Hotels in total.
Extracting flight pricing is a bigger challenge. For getting the inexpensive round-trip flights for 100 destinations for more than 5 various dates all, it is 500 pages. However, flights don’t have the destination airport — so they also find a source airport. These 500 flights need to get checked from all origin airports. We need to check flights to the Aspen from all airports around NYC, all airports around Los Angeles, as well as all airport in between. We don’t find this additional origin airport “dimension” while scraping hotels. It means you have many orders of scaling more flight pricing than the hotel prices applicable to the problem.
Scraping Flights Data
The objective here is to get the cheapest flights between every origin or destination pair for the provided date sets. For doing that, we fetch about 300,000 flight prices from around 25,000 Google Flights pages daily. It isn’t a cosmological number, however, it’s sufficient enough that we need to take care of the cost efficiency. In the last year, we’ve repeated our scraping practice to get a fairly flexible and robust solution.
Simple Queue Service (SQS) by AWS
We have used SQS for serving a queue about URLs to scrape. Google Flights URLs just look like:
https://www.google.com/flights?hl=en#flt=BOS.JFK,LGA,EWR.2020-11-13*JFK,LGA,EWR.BOS.2020-11-16;c:USD;e:1;sd:1;t:f

A three-letter code in this URL indicates an IATA airport code. In case, you click the link, you will notice that there are many destination airports. That is one key for effective Google Flights extraction! As Google Flights permits for different trips to get searched, we can get the economical prices for different round-trips at one page. Sometimes, Google won’t display flights for different trips queried. For making sure that we get all the required data, we find when the origin or destination isn’t shown in the results, then re-queuing the trip for getting searched on its own. It makes sure that we get the prices of the discounted flights accessible for every trip.
One SQS queue saves all the Google Flights URLs required to get crawled. While a crawler runs, this will choose the message from a queue. Ordering is not that important, therefore a normal queue is utilized. Here’s what a queue looks when it has so many messages:

AWS Lambda (with Chalice)
Lambda is the place where a crawler actually works. We utilize Chalice that is an outstanding Lambda micro framework for Python for deploying functions with Lambda. Though Serverless is the most widespread Lambda framework, this is well-written in NodeJS. That is turn-off to us provided that we’re the most well-known with Python as well as wish to keep the stack unchanging. We’ve been extremely happy with the Chalice — this is as easy as Flask for using, as well as it permits the whole Brisk Voyage backend for getting Python on the Lambda.
The crawler includes two Lambda functions:
The main Lambda function consumes messages from a SQS queue, scrapes Google Flights as well as stores the outputs. While the function works, it launches the Chrome browser for Lambda example as well as crawls page. We define that as the pure Lambda functioning having Chalice, because this function would get separately triggered:
@app.lambda_function()
def crawl(event, context):
...
The 2nd Lambda function activates different instances of initial function. This works as many scrapers as we require in parallel. The function gets defined for running at a couple of minutes past an hour during the UTC hours with 15–22 on a daily basis. It begins 50 instances of a primary crawl functioning for 50 similar crawlers:
@app.schedule(“cron(2 15,16,17,18,19,20,21,22 ? * * *)”)
def start_crawlers(event):
app.log.info(“Starting crawlers.”)
n_crawlers = 50
client = boto3.client(“lambda”)
for n in range(n_crawlers):
response = client.invoke(
FunctionName=”collector-dev-crawl”,
InvocationType=”Event”,
Payload=’{“crawler_id”: ‘ + str(n) + “}”,
)
app.log.info(“Started crawlers.”)
A substitute would be to utilize a SQS queue like an event resource for a crawl function, to facilitate when a queue populates, different crawlers automatically increase. We have originally utilizes this approach. But, there is a huge drawback, although: total number of messages, which can be consumed by a batch size is 10, it means that a function needs to be newly invoked for all groups of 10 messages. That causes compute incompetence, and also increases the bandwidth severely as a browser cache gets destroyed each time when a function restarts. Many ways are there around that, however, in our experiences, they have led to additional complexity.
One Note on the Lambda Costing
Lambda costs around $0.00001667 per GB per second, whereas a lot of EC2 examples cost only one-sixth of it. We presently pay about $50 per month for Lambda, therefore this would indicate that we can significantly reduce the costs. However, Lambda is having two big advantages: it can scale up as well as down immediately with zero efforts so we are not paying for the idling server and second, that’s what rest of the stack is created on. Lesser technology means lesser cognitive overhead. In case, total pages we scrape ramps up, that would add up to reexamine EC2 or similar compute services. At that point, an additional $40 every month ($50 for Lambda vs. ~$10 for EC2) is worth it.
Pyppeteer
It is a Python library to interact with Puppeteer, a headless Chrome API. As Google Flights needs Javascript for loading prices, this is required to render a complete page. All the 50 crawling functions launch their own copy of the headless Chrome browser that is well-controlled by Pyppeteer.
Working with a headless Chrome using Lambda was challenging. We need to pre-package required libraries in Chalice, which were not pre-installed at Amazon Linux, an OS, which Lambda works on the top. All these libraries get added into a vendor directory within the Chalice project that tells Chalice for installing them on all Lambda crawling instances:
As 50 crawling functions turn on above ~5 seconds, Chrome examples are launched in every function. It is the powerful system; this could scale in thousands of contemporary Chrome examples by changing a single line of code.
When a page loads as well as renders, a rendered HTML could be scraped, as well as the flight pricing, airlines, as well as times could be read from a page. About 10–15 flight results are there per page, which we wish to scrape (we mainly care about the low-priced, however, the others could be helpful too). It is presently done manually through traversing a page structure, however, it is fragile. The crawler could break in case, Google changes an element on a page.
When the prices get extracted, we delete a SQS message, as well as re-queue all origin or destinations, which weren’t shown within flight results. Then, we then to the subsequent page — any new URL gets pulled from a queue, as well as the procedure repeats. After initial page crawled with every crawl example, pages need lesser bandwidth for loading (~100kb rather than 3 MB) because of Chrome’s caching. It means we require to keep instance active as long as possible, as well as crawl maximum trips we can to preserve cache. As it’s beneficial to go with the functions of retaining the cache, scraping‘s timeout turns into 15 minutes that is the maximum time AWS presently allows.
DynamoDB
After it has scraped from a page, we need to store flight data. We have chosen DynamoDB for that as it has on-demands’ scaling. It was vital for us because we were not sure about what type of loads we will need. It’s also affordable, and 25GB is free under the AWS’s Free Tier.
Usually, tables could only have a primary index having one kind of key. Adding subordinate indices is quite possible, however limited or needed extra provisioning that is increases the costs. Because of this limitation about indices, DynamoDB works in the best way when usage is well-thought-out before. It has taken a couple of tries to find the table designs right. In recollection, DynamoDB is a bit inflexible for all types of products we’re creating. Aurora Serverless provides PostgreSQL so we need to probably switch towards it at some point of time.
Nevertheless, we save all the flight data in one table. An index has the primary key about IATA code of a destination airport, as well as the secondary range keys that are ULID.
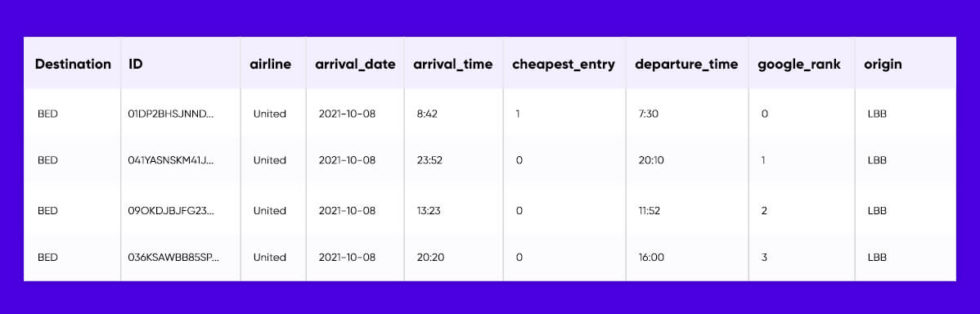
ULIDs are wonderful for DyanmoDB as they are distinctive, have a surrounded timestamp, as well as are lexicographically sortable through the timestamp. It permits the range keys to both help as the unique identifier as well as support queries like “provide me the discounted trips to BED, which we’ve scraped in the last 30 minutes”:
response = crawled_flights_table.query(
KeyConditionExpression=Key("destination").eq(iata_code) & Key("id").gt(earliest_id),
FilterExpression=Attr("cheapest_entry").eq(1),
)
Testing & Monitoring
We have used Dashbird to monitor the crawler as well as everything else which runs under Lambda. Efficient monitoring is the requirement for extracting applications as page structural changes are a continuous danger. During any time, a page structure could change that breaks a crawler. We require to get alerted whenever this happens. We have a couple of separate mechanisms for tracking that:
A Dashbird alert, which emails us while there is the crawl failure.
Conclusion
The grouping of Lambda, Chalice, SQS, Pyppeteer, Dashbird, DynamoDB, and GitHub worked fine for us. This is a lower-overhead solution, which is completely Python, needs no example provisioning, as well as keeps the costs comparatively low.
As we’re completely satisfied with it at our present scale of around 300k pricing as well as 25k pages every day, there is ample room for improvements as data needs to grow:
Initially, we need to move to the EC2 servers, which are automatically provisioned if required. As we scrape more, the data cost between EC2 and Lambda will increase for the point whereas it would make sense for running on the EC2. It will cost around 1/5th of the Lambda for compute, and also will need extra overhead as well as won’t decrease the bandwidth costs.
Second, we might move to Serverless Aurora from DynamoDB that permits for more supple data usage. It will be helpful as our price library as well as appetite for the alternative data utilizes grow.
For more information about Scraping Google Flights Data, contact X-Byte Enterprise Crawling or ask for a free quote!
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯

Related Blogs

Manufacturer Price Intelligence: Real-Time Dealer & Distributor Feed




