

There is so much data available online than the human being can use in the lifetime. So, you not only need access to all the information, but also an accessible way of collecting, organizing, and analyzing it.
You require web data scraping.
Data scraping inevitably scrapes data as well as presents that in the format that you could easily understand. Here in the tutorial, we’ll concentrate on web scraping’s applications in financial markets as web data scraping could be utilized in different situations.
In case, you’re a passionate investor, having closing prices daily could be a problem, particularly when the data you require is found on many webpages. At X-Byte, we can make data scraping easier through creating a web data scraper to repossess stock files automatically online.
How to Start?
We will utilize Python as the web scraping language, in cooperation with an easy and commanding library, BeautifulSoup.
The Windows users need to install Python from its official website.
The Mac users will have Python pre-installed within the OS X. So, just open the terminal as well as type the python –version and you will be able to see the python version 2.7.x.
After that, we have to get BeautifulSoup library through pip, the package management tools of Python.
Open the terminal and types:
easy_install pip pip install BeautifulSoup4
Note: In case, you fail in executing the command line above, try to add sudo before every line.
The first step in web scraping is to find the website URL we want to scrape. We can start by looking at the TripAdvisor home page. From there, we can navigate to the page for a specific hotel.
The Fundamentals
Before we begin coding, let’s recognize the fundamentals of HTML as well as some guidelines of web data scraping.
The HTML Tags
In case, you already know about the HTML tags, you can skip this section.
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1> First Scraping </h1>
<p> Hello World </p>
<body>
</html>
It is the fundamental syntax of the HTML webpages. Each <tag> works a block within a web page:
- <!DOCTYPE html>: All HTML documents have to begin with the type declarations.
- Any HTML documents are limited between the <html> as well as </html>.
- A script and Meta declaration about HTML documents is among <head> as well as </head>.
- A visible part about HTML documents is among <body> as well as </body> tags.
- The title headings can be defined with <h1> throughout <h6> tags.
- The paragraphs can be defined using a <p> tag.
Other suitable tags consist of <a> to do hyperlinks, <table> to do tables, <tr> to do table rows, as well as <td> to do table columns.
At times, HTML tags come with class or ID attributes. An ID attribute requires a distinctive ID for the HTML tags as well as the value has to be unique with HTML documents. The class attributes are utilized to describe equal style for the HTML tags having the similar class. We could use these classes as well as IDs to assist us find the required data.
To get more details on the HTML tags, class and ID, you can refer to the W3Schools Tutorials.
Web Scraping Guidelines
You need to check the Terms & Conditions of a website before scraping it. You need to be careful about reading the statements regarding legal data use. Normally, the data scrapped should not get utilized for commercial objectives.
You should not request information from a website too destructively with the program (also identified as spamming), because this might break a website. Ensure that your program works in a sensible way (i.e. works like the human). A request for the webpage every second can be a good job.
The website layout might change repeatedly, so ensure to revisit a site as well as rewrite the code as required.
Page Inspection
Let’s use one page of Bloomberg Quote site as a model.
As somebody observing the stock markets, we would love to get an index name (here it is S&P 500) as well as its pricing from the page. Initially, right-click as well as open the browser’s examiner to review the webpage.
Your content goes here. Edit or remove this text inline or in the module Content settings. You can also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.
Also, in case you hover as well as click name called “S&P 500 Index”, this is within <div class=”basic-quote”> as well as <h1 class=”name”>.
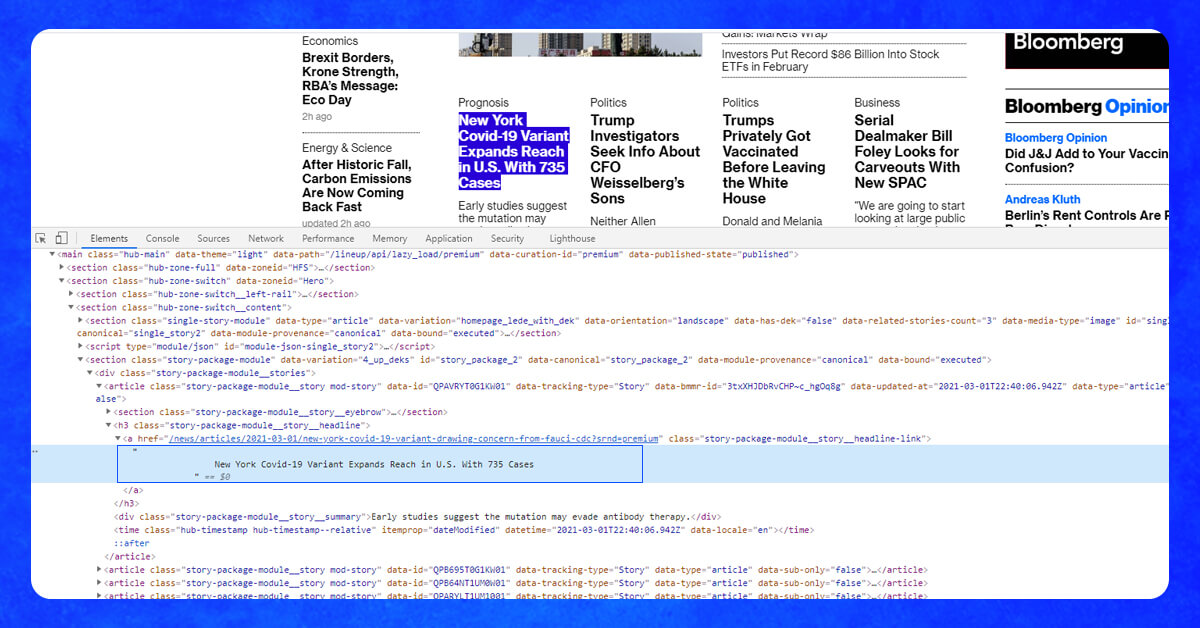
Currently, we understand the distinctive location of the data using class tags.
Go Through the Codes
Now as we know the data location, we can begin coding the web scraper. Just open the text editor!
Initially, we have to import different libraries, which will be used.
# import libraries import urllib2 from bs4 import BeautifulSoup
After that, declare the variables for a page URL.
# query the website and return the html to the variable ‘page’ page = urllib2.urlopen(quote_page)
In the end, parse a page in the BeautifulSoup formats so that we can utilize BeautifulSoup for working on that.
# parse an html with beautiful soup as well as store in the variable `soup`
soup = BeautifulSoup(page, ‘html.parser’)
As we have the variable, soup, having HTML of a page. Now, we can begin coding, which scrapes the data.
Keep in mind the exclusive layers of data. The BeautifulSoup can assist us in getting into those layers as well as scrape content using find(). Here, as an HTML class names are distinctive on the page, we could just query <div class=”name”>.
# Take out the
Subsequently getting the tags, we would get data through getting the text.
Your content goes here. Edit or remove this text inline or in the module Content settings. You can also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.
name = name_box.text.strip() # strip() is used to remove starting and trailing print name
Subsequently getting the tags, we would get data through getting the text.
name = name_box.text.strip() # strip() is used to remove starting and trailing print name
Correspondingly, we can have the pricing also.
# get the index price
price_box = soup.find(‘div’, attrs={‘class’:’price’})
price = price_box.text
print price
Whenever you run a program, you need to observe that this prints out current pricing of S&P 500 Index.
Exporting to the Excel CSV
As we get the data, we need to save that. A good option is Excel’s Comma’s Separated Format. This could be opened within the Excel so that you can observe the data as well as get it easily.
However, initially, we need to import Python CSV component as well as date time module for getting record date. Add these lines in the code in import segment.
import csv from datetime import datetime
In the end of the code, just add a code of writing data into the CSV files.
# open a csv file with append, so old data will not be erased with open(‘index.csv’, ‘a’) as csv_file: writer = csv.writer(csv_file) writer.writerow([name, price, datetime.now()])
In case, you are running a program, you need to export the index.csv files that you can open using Excel whereas you need to see the data line.
Therefore, if you are running this program daily, you would get S&P 500 Index pricing without digging through the site!
Go Further (Innovative Uses)
Different Indices
So, if extracting single index is insufficient for you then we could try to scrape different indices at same time.
Initially, modify quote_page in the arrays of the URL.
quote_page = [‘http://www.bloomberg.com/quote/SPX:IND', ‘http://www.bloomberg.com/quote/CCMP:IND']
After that, we alter the data scraping code into the for-loop that will use the URLs in sequence as well as store all data in the variable data.
# for loop data = [] for pg in quote_page: # query the website and return the html to the variable ‘page’ page = urllib2.urlopen(pg) # parse the html using beautiful soap and store in variable `soup` soup = BeautifulSoup(page, ‘html.parser’) # Take out the
Moreover, change the saving segment for saving information rows by rows.
# open a csv file with append, so old data will not be erased with open(‘index.csv’, ‘a’) as csv_file: writer = csv.writer(csv_file) # The for loop for name, price in data: writer.writerow([name, price, datetime.now()])
Repeat the program as well as you need to scrape two indices together!
Innovative Web Scraping Methods
BeautifulSoup is easy and wonderful for smaller-scale data scraping. However, in case you want to scrape data at the bigger scale, then you should think about using other options:
Scrapy, a dominant Python scraper framework
Try and integrate the code using a few public APIs. Data efficiency recovery is much bigger than extracting webpages. For instance, just look at the Facebook Graph APIs that can assist you in getting hidden data that is not displayed on the Facebook webpages.
Think about using the database backend including MySQL for storing data when this gets too big.
Use the DRY Technique
DRY means “Don’t Repeat Yourself” and try and automate the daily tasks. A few other fun –giving projects to think about might be to keep track of the Facebook friends’ real time (having their agreement certainly), or grab the topics list in the forum as well as try the natural languages processing (it is the hot topic in Artificial Intelligence). In case, you have some queries, you can leave in the comment section or contact us for any website data scraping services requirements.
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯











