

Our web scraping service for ecommerce serves to companies with a variety of needs and data dependencies, ranging from new entrants to established online merchants.
Scraping e-commerce sites allows you to simultaneously scrape data feeds from multiple ecommerce reference sites, partners, and channels. We make it simple for you to gather information about product data regularly in the format you want the data.
'''
!pip install scrapy
!pip install tabulate
''''\n!pip install scrapy\n!pip install tabulate\n'import os
import logging
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scrapy
from scrapy.crawler import CrawlerProcess
from glob import glob
import glob, os
from ipywidgets import widgets
from IPython.display import display, clear_output
from tabulate import tabulate
pd.set_option('display.max_colwidth', None)
import warnings
warnings.filterwarnings('ignore')CONST_USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
CONST_PRODUCT = 'Product'
CONST_URL = 'Url'
CONST_PLATFORM = 'Platform'
CONST_MAX_PAGE_COUNT = 'Max_Page_Count'
CONST_PRODUCT_NAME = 'Product_Name'
CONST_PRODUCT_COST = 'Product_Cost'
CONST_PRODUCT_BEVERAGES = 'Beverages'
CONST_PRODUCT_BEVERAGES_TEA = 'Tea'
CONST_PRODUCT_BEVERAGES_COFFEE = 'Coffee'
CONST_PRODUCT_GROCERRIES = 'Grocery'
CONST_PRODUCT_MASALA_AND_SPICES = 'Masala & Spices'
CONST_PLATFORM_BIGBASKET = 'BigBasket'
CONST_PLATFORM_DMART = 'Dmart'
CONST_PLATFORM_AMAZON = 'Amazon'
CONST_PLATFORM_FLIPKART = 'Flipkart'
CONST_DF_FORMAT_CSV = '.csv'
CONST_DF_FORMAT_JSON = '.json'
CONST_NOT_APPLICABLE = 'N/A'
(A) Data Acquisition
Data is scraped from various platforms such as
- Amazon
- Big Basket
- DMart
- Flipkart
• DF_Save_Format = CONST_DF_FORMAT_CSV
class Base_Spider():
''' This is the base class for all the custom data scrappers. '''
def __init__():
''' Base Constructor'''
custom_settings = {
'LOG_LEVEL': logging.WARNING,
'FEED_FORMAT':'csv',
}
def save(self, df, filename, domain):
path = 'outputs'
if not os.path.exists(path):
os.makedirs(path)
if DF_Save_Format == CONST_DF_FORMAT_CSV:
df.to_csv(path + '/' + domain + '_' + filename + CONST_DF_FORMAT_CSV)
elif DF_Save_Format == CONST_DF_FORMAT_JSON:
df.to_json(path + '/' + domain + '_' + filename + CONST_DF_FORMAT_JSON)class Amazon_Spider(scrapy.Spider, Base_Spider):
''' Spider to crawl data from Amazon sites. '''
name = 'amazon'
product = None
allowed_domains = ['amazon.in']
url = None
max_page_count = 0
custom_settings = {
**Base_Spider.custom_settings,
'FEED_URI': 'outputs/amazonresult' + DF_Save_Format
}
def __init__(self, product=None, url = None, max_page_count = None, *args, **kwargs):
super(Amazon_Spider, self).__init__(*args, **kwargs)
self.product = product
self.start_urls.append(url)
def parse(self, response):
if response.status == 200:
for url in response.xpath('//ul[@id="zg_browseRoot"]/ul/ul/li/a/@href').extract():
yield scrapy.Request(url = url, callback = self.parse_product, errback = self.errback_httpbin, dont_filter=True)
def parse_product(self, response):
#Extract data using css selectors
for product in response.xpath('//ol[@id="zg-ordered-list"]//li[@class="zg-item-immersion"]').extract():
product_name = response.xpath('//li[@class="zg-item-immersion"]//div[@class="a-section a-spacing-small"]/img/@alt').extract()
product_price = response.xpath('//span[@class="p13n-sc-price"]/text()').extract()
product_rating = response.xpath('//div[@class="a-icon-row a-spacing-none"]/a/@title').extract()
#product_category = response.xpath('//span[@class="category"]/text()').extract()
#Making extracted data row wise
for item in zip(product_name,product_price,product_rating):
#create a dictionary to store the scraped info
scraped_info = {
#key:value
'product_name' : item[0], #item[0] means product in the list and so on, index tells what value to assign
'price' : item[1],
'rating' : item[2],
'category' : response.xpath('//span[@class="category"]/text()').extract(),
}
yield scraped_info
def errback_httpbin(self, failure):
# log all failures
# in case you want to do something special for some errors,
# you may need the failure's type:
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
self.logger.error('HttpError on %s', response.url)class BigBasket_Spider(scrapy.Spider, Base_Spider):
''' Spider to crawl data from BigBasket sites. '''
name = 'bigbasket'
allowed_domains = ['bigbasket.com']
max_page_count = 0
custom_settings = {
'LOG_LEVEL': logging.WARNING,
}
def __init__(self, product=None, url = None, max_page_count = None, *args, **kwargs):
super(BigBasket_Spider, self).__init__(*args, **kwargs)
self.product = product
if self.product == CONST_PRODUCT_BEVERAGES_TEA:
for i in range(2, int(max_page_count)):
self.start_urls.append(url[0:(url.rfind('page=')+5)] + str(i) + url[(url.rfind('page=')+6):])
elif self.product == CONST_PRODUCT_BEVERAGES_COFFEE:
for i in range(2, int(max_page_count)):
self.start_urls.append(url[0:(url.rfind('page=')+5)] + str(i) + url[(url.rfind('page=')+6):])
def get_json(self, response):
if self.product == CONST_PRODUCT_BEVERAGES_TEA or self.product == CONST_PRODUCT_BEVERAGES_COFFEE:
return json.loads(response.body)['tab_info']['product_map']['all']['prods']
def parse(self, response):
url = str(response.url)
data = self.get_json(response)
cols= ['p_desc', 'mrp', 'sp', 'dis_val', 'w','store_availability', 'rating_info']
df = pd.DataFrame(columns = cols)
for item in data:
df = df.append(pd.Series({k: item[k] if k != 'store_availability' else 'A' \
in [i['pstat'] for i in item[k]] if k != 'rating_info' else item['rating_info']['avg_rating'] for k in cols}), ignore_index = True)
df[['dis_val','mrp','sp']] = df[['dis_val','mrp','sp']].apply(pd.to_numeric)
df['dis_val'].fillna(0, inplace=True)
df['dis_val'] = (df['mrp']/100) * df['dis_val']
#display(df)
self.save(df, self.product + '_' + str(url[url.rfind('page=') + 5:url.rfind('&tab_type')]), BigBasket_Spider.name)class Dmart_Spider(scrapy.Spider, Base_Spider):
''' Spider to crawl data from Dmart sites. '''
name = 'dmart'
allowed_domains = ['dmart.in']
max_page_count = 0
custom_settings = {
'LOG_LEVEL': logging.WARNING,
}
def __init__(self, product=None, url = None, max_page_count = None, *args, **kwargs):
super(Dmart_Spider, self).__init__(*args, **kwargs)
self.product = product
if self.product == CONST_PRODUCT_BEVERAGES or self.product == CONST_PRODUCT_GROCERRIES or self.product == CONST_PRODUCT_MASALA_AND_SPICES:
self.start_urls.append(url)
def get_json(self, response):
if self.product == CONST_PRODUCT_BEVERAGES or self.product == CONST_PRODUCT_MASALA_AND_SPICES:
return json.loads(response.body)['products']['suggestionView']
elif self.product == CONST_PRODUCT_GROCERRIES:
return json.loads(response.body)['suggestionView']
def parse(self, response):
data = self.get_json(response)
cols= ['name', 'price_MRP', 'price_SALE', 'save_price', 'defining','buyable']
df = pd.DataFrame(columns = cols)
for item in data:#
df = df.append(pd.Series({k: item['skus'][0].get(k) for k in cols}), ignore_index = True)
#print('\n---------------------------------' + self.product + '-------------------------------------------')
#display(df)
self.save(df, self.product, Dmart_Spider.name)class Flipkart_Spider(scrapy.Spider, Base_Spider):
''' Spider to crawl data from Flipkart sites. '''
name = 'flipkart'
allowed_domains = ['flipkart.in']
max_page_count = 0
custom_settings = {
**Base_Spider.custom_settings,
'FEED_URI': 'outputs/flipkartresult' + DF_Save_Format
}
def __init__(self, product=None, url = None, max_page_count = None, *args, **kwargs):
super(Flipkart_Spider, self).__init__(*args, **kwargs)
self.product = product
self.start_urls = [
'https://www.flipkart.com/search?q=beverages%20in%20tea&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off',
'https://www.flipkart.com/search?q=tea&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=2',
'https://www.flipkart.com/search?q=tea&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=3',
'https://www.flipkart.com/search?q=coffee&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off',
'https://www.flipkart.com/search?q=coffee&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=2',
'https://www.flipkart.com/search?q=coffee&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=3',
'https://www.flipkart.com/search?q=spices&as=on&as-show=on&otracker=AS_Query_OrganicAutoSuggest_4_4_na_na_na&otracker1=AS_Query_OrganicAutoSuggest_4_4_na_na_na&as-pos=4&as-type=RECENT&suggestionId=spices&requestId=94f8bdaf-8357-487a-a68b-e909565784e7&as-searchtext=s%5Bpic',
'https://www.flipkart.com/search?q=spices&as=on&as-show=on&otracker=AS_Query_OrganicAutoSuggest_4_4_na_na_na&otracker1=AS_Query_OrganicAutoSuggest_4_4_na_na_na&as-pos=4&as-type=RECENT&suggestionId=spices&requestId=94f8bdaf-8357-487a-a68b-e909565784e7&as-searchtext=s%5Bpic&page=2',
'https://www.flipkart.com/search?q=spices&as=on&as-show=on&otracker=AS_Query_OrganicAutoSuggest_4_4_na_na_na&otracker1=AS_Query_OrganicAutoSuggest_4_4_na_na_na&as-pos=4&as-type=RECENT&suggestionId=spices&requestId=94f8bdaf-8357-487a-a68b-e909565784e7&as-searchtext=s%5Bpic&page=3',
'https://www.flipkart.com/search?q=grocery&sid=7jv%2Cp3n%2C0ed&as=on&as-show=on&otracker=AS_QueryStore_OrganicAutoSuggest_2_8_na_na_ps&otracker1=AS_QueryStore_OrganicAutoSuggest_2_8_na_na_ps&as-pos=2&as-type=RECENT&suggestionId=grocery%7CDals+%26+Pulses&requestId=749df6fb-1916-45df-a5f6-e2445a67b7ce&as-searchtext=grocery%20',
'https://www.flipkart.com/search?q=grocery&sid=7jv%2Cp3n%2C0ed&as=on&as-show=on&otracker=AS_QueryStore_OrganicAutoSuggest_2_8_na_na_ps&otracker1=AS_QueryStore_OrganicAutoSuggest_2_8_na_na_ps&as-pos=2&as-type=RECENT&suggestionId=grocery%7CDals+%26+Pulses&requestId=749df6fb-1916-45df-a5f6-e2445a67b7ce&as-searchtext=grocery+&page=2',
'https://www.flipkart.com/search?q=grocery+1+rs+offer+all&sid=7jv%2C72u%2Cd6s&as=on&as-show=on&otracker=AS_QueryStore_OrganicAutoSuggest_6_7_na_na_ps&otracker1=AS_QueryStore_OrganicAutoSuggest_6_7_na_na_ps&as-pos=6&as-type=RECENT&suggestionId=grocery+1+rs+offer+all%7CEdible+Oils&requestId=c19eb0d1-779c-4ae6-9b5a-3f156db29852&as-searchtext=grocery',
'https://www.flipkart.com/search?q=grocery&sid=7jv%2C30b%2Cpne&as=on&as-show=on&otracker=AS_QueryStore_OrganicAutoSuggest_4_7_na_na_ps&otracker1=AS_QueryStore_OrganicAutoSuggest_4_7_na_na_ps&as-pos=4&as-type=RECENT&suggestionId=grocery%7CNuts+%26+Dry+Fruits&requestId=06270ce4-4dc6-4669-9a72-ce708331f98b&as-searchtext=grocery',
]
def parse(self, response):
for p in response.css('div._3liAhj'):
yield {
'Category': response.css('span._2yAnYN span::text').extract_first(),
'itemname': p.css('a._2cLu-l::text').extract_first(),
'price(₹)': p.css('a._1Vfi6u div._1uv9Cb div._1vC4OE::text').extract_first()[1:],
'MRP(₹)' : p.css('a._1Vfi6u div._1uv9Cb div._3auQ3N::text').extract(),
'discount': p.css('a._1Vfi6u div._1uv9Cb div.VGWI6T span::text').extract_first(),
'rating': p.css('div.hGSR34::text').extract_first(),
'itemsdeliverable' : p.css('span._1GJ2ZM::text').extract()
}process = CrawlerProcess({
#'USER_AGENT': CONST_USER_AGENT,
'LOG_ENABLED' : False
})
products = [
{
CONST_PLATFORM : CONST_PLATFORM_BIGBASKET,
CONST_PRODUCT: CONST_PRODUCT_BEVERAGES_TEA,
CONST_URL : 'https://www.bigbasket.com/product/get-products/?slug=tea&page=1&tab_type=[%22all%22]&sorted_on=relevance&listtype=ps',
CONST_MAX_PAGE_COUNT:'10'
},
{
CONST_PLATFORM : CONST_PLATFORM_BIGBASKET,
CONST_PRODUCT: CONST_PRODUCT_BEVERAGES_COFFEE,
CONST_URL : 'https://www.bigbasket.com/product/get-products/?slug=coffee&page=1&tab_type=[%22all%22]&sorted_on=relevance&listtype=ps',
CONST_MAX_PAGE_COUNT:'10'
},
{
CONST_PLATFORM : CONST_PLATFORM_AMAZON,
CONST_PRODUCT: CONST_PRODUCT_BEVERAGES_TEA,
CONST_URL: 'https://www.amazon.in/gp/bestsellers/grocery/ref=zg_bs_nav_0',
CONST_MAX_PAGE_COUNT:'1'
},
{
CONST_PLATFORM : CONST_PLATFORM_DMART,
CONST_PRODUCT : CONST_PRODUCT_BEVERAGES,
CONST_URL : 'https://digital.dmart.in/api/v1/clp/15504?page=1&size=1000',
CONST_MAX_PAGE_COUNT : '1'
},
{
CONST_PLATFORM : CONST_PLATFORM_DMART,
CONST_PRODUCT : CONST_PRODUCT_GROCERRIES,
CONST_URL : 'https://digital.dmart.in/api/v1/search/grocery?page=1&size=1000',
CONST_MAX_PAGE_COUNT : '1'
},
{
CONST_PLATFORM : CONST_PLATFORM_DMART,
CONST_PRODUCT : CONST_PRODUCT_MASALA_AND_SPICES,
CONST_URL : 'https://digital.dmart.in/api/v1/clp/15578?page=1&size=1000',
CONST_MAX_PAGE_COUNT : '1'
},
{
CONST_PLATFORM : CONST_PLATFORM_FLIPKART,
CONST_PRODUCT : None,
CONST_URL : None,
CONST_MAX_PAGE_COUNT : '1'
},
]
for item in products:
if item[CONST_PLATFORM] == CONST_PLATFORM_DMART:
process.crawl(Dmart_Spider, item[CONST_PRODUCT], item[CONST_URL], item[CONST_MAX_PAGE_COUNT])
#continue
elif item[CONST_PLATFORM] == CONST_PLATFORM_AMAZON:
process.crawl(Amazon_Spider, item[CONST_PRODUCT], item[CONST_URL], item[CONST_MAX_PAGE_COUNT])
#continue
elif item[CONST_PLATFORM] == CONST_PLATFORM_BIGBASKET:
process.crawl(BigBasket_Spider, item[CONST_PRODUCT], item[CONST_URL], item[CONST_MAX_PAGE_COUNT])
#continue
elif item[CONST_PLATFORM] == CONST_PLATFORM_FLIPKART:
process.crawl(Flipkart_Spider, item[CONST_PRODUCT], item[CONST_URL], item[CONST_MAX_PAGE_COUNT])
#continue
process.start()
(B) Data Cleaning
df_amazon = pd.concat(map(pd.read_csv, glob.glob(os.path.join('', "outputs/amazon*.csv"))))
df_amazon.head()
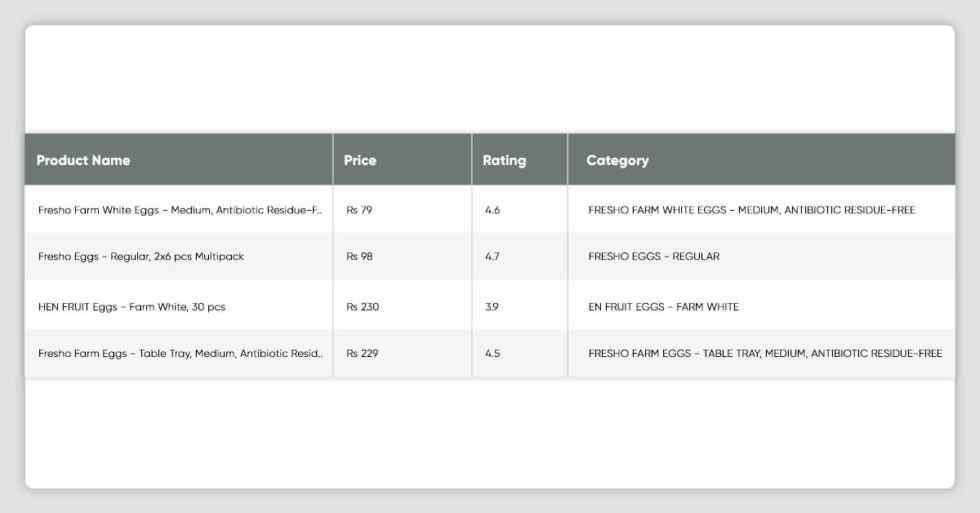
# df_amazon[df_amazon.duplicated(['product_name'])]
df_amazon.drop_duplicates(subset ="product_name", keep = 'first', inplace = True)df_amazon[df_amazon['product_name'] == 'product_name'].head()

df_amazon[df_amazon['product_name'] == 'product_name'].shape(1, 4)df_amazon.drop(df_amazon[df_amazon['product_name'] == 'product_name'].index, inplace = True)df_amazon['rating'].unique()array(['3.8 out of 5 stars', '3.0 out of 5 stars', '3.5 out of 5 stars',
'3.9 out of 5 stars', '4.0 out of 5 stars', '4.2 out of 5 stars',
'3.6 out of 5 stars', '4.1 out of 5 stars', '4.4 out of 5 stars',
'4.5 out of 5 stars', '3.7 out of 5 stars', '4.3 out of 5 stars',
'2.7 out of 5 stars', '1.0 out of 5 stars', '2.5 out of 5 stars',
'4.6 out of 5 stars', '4.8 out of 5 stars', '2.9 out of 5 stars',
'3.3 out of 5 stars', '3.2 out of 5 stars', '2.3 out of 5 stars',
'1.3 out of 5 stars', '4.7 out of 5 stars', '5.0 out of 5 stars',
'3.1 out of 5 stars', '3.4 out of 5 stars', '2.4 out of 5 stars',
'2.8 out of 5 stars', '2.6 out of 5 stars', '2.2 out of 5 stars',
'2.0 out of 5 stars', '4', '.', '3', ' ', 'o', 'u', 't', '0'],
dtype=object)exclude = [' ', '.','o', 'u', 't' ]
df_amazon.drop(df_amazon[df_amazon['rating'].isin(exclude)].index, inplace = True)df_amazon['rating'] = df_amazon.apply(lambda x: x.rating[0:3] ,axis=1)df_amazon['price'] = df_amazon['price'].replace('₹', '', regex=True).replace(',', '', regex=True)df_amazon['price'] = df_amazon['price'].replace('\xa0', '', regex=True)df_amazon['price'] = df_amazon['price'].str.strip()df_amazon.drop(df_amazon[df_amazon['price'] == ''].index, inplace = True)df_amazon.dtypesproduct_name object
price object
rating object
category object
dtype: objectdf_amazon['rating'].unique()array(['3.8', '3.0', '3.5', '3.9', '4.0', '4.2', '3.6', '4.1', '4.4',
'4.5', '3.7', '4.3', '2.7', '1.0', '2.5', '4.6', '4.8', '2.9',
'3.3', '3.2', '2.3', '1.3', '4.7', '5.0', '3.1', '3.4', '2.4',
'2.8', '2.6', '2.2', '2.0', '3', '0', '4'], dtype=object)df_amazon[['rating', 'price']] = df_amazon[['rating', 'price']].astype(np.float)df_amazon['SpecialPrice'] = df_amazon['price']
df_amazon['Discount'] = 0.0df_amazon['IsAvailable'] = Truedf_amazon['Platform'] = CONST_PLATFORM_AMAZONdf_amazon.columnsIndex(['product_name', 'price', 'rating', 'category', 'SpecialPrice',
'Discount', 'IsAvailable', 'Platform'],
dtype='object')df_amazon.columns = ['ProductName', 'ActualPrice', 'Rating', 'Category', 'SpecialPrice', 'Discount','IsAvailable', 'Platform']df_amazon.dtypesProductName object
ActualPrice float64
Rating float64
Category object
SpecialPrice float64
Discount float64
IsAvailable bool
Platform object
dtype: objectdf_amazon.head()nplace = True)df_amazon[df_amazon['product_name'] == 'product_name'].head()
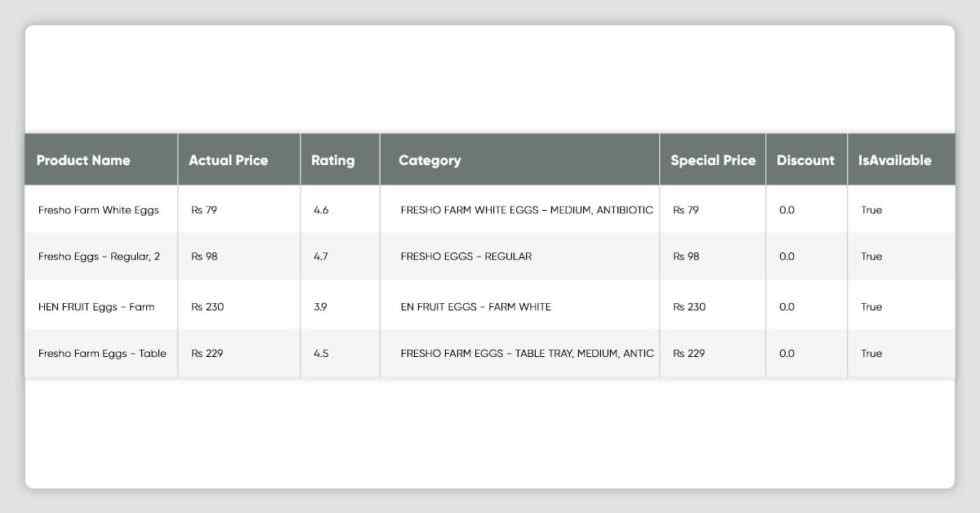
df_amazon.isna().any()ProductName False
ActualPrice False
Rating False
Category False
SpecialPrice False
Discount False
IsAvailable False
Platform False
dtype: booldf_bigbasket = pd.concat(map(pd.read_csv, glob.glob(os.path.join('', "outputs/bigbasket*.csv"))))
df_bigbasket.head()
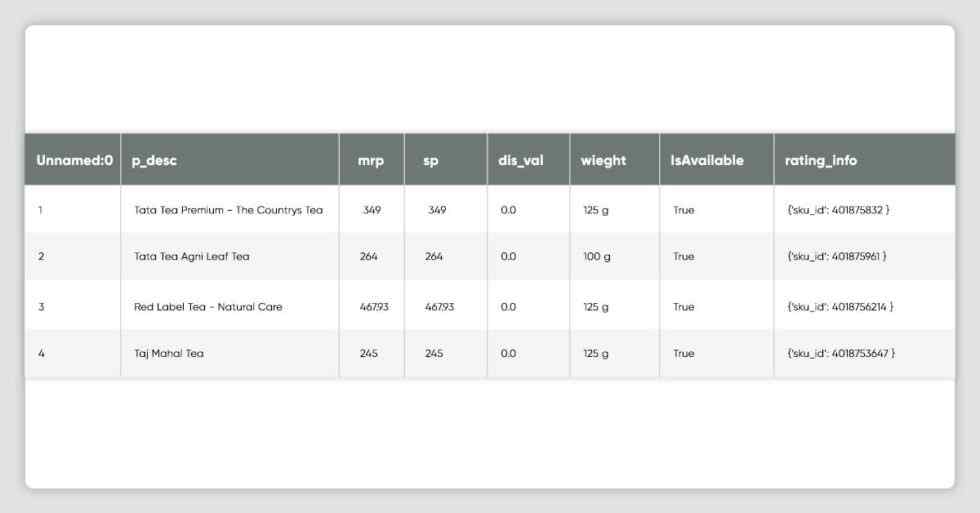
df_bigbasket.shape(320, 8)df_bigbasket.drop('Unnamed: 0', axis=1,inplace=True)df_bigbasket.drop('w', axis=1,inplace=True)df_bigbasket['rating_info'].fillna(CONST_NOT_APPLICABLE, inplace = True)def get_bigbasket_ratings(x):
if 'avg_rating' in x:
rating_index = x.rfind('avg_rating')
l = len('avg_rating')
m = x[(rating_index+l):].find(',')
n = x[(rating_index+l) : (rating_index+l + m)].split(':')
if len(n) > 1:
return n[1]
else:
return n[0]
else:
return CONST_NOT_APPLICABLEdf_bigbasket['rating_info'] = df_bigbasket.apply(lambda x: get_bigbasket_ratings(x.rating_info), axis=1)df_bigbasket['rating_info'].unique()array(['N/A', ' 1', ' 5', ' 3', ' 4.1', ' 4.2', ' 4.4', ' 4.3', ' 3.5',
' 3.2', ' 2.5', ' 4.6', ' 4.7', ' 4.8', ' 4', ' 4.5', ' 3.7',
' 3.6', ' 3.9'], dtype=object)df_bigbasket['Category'] = CONST_PRODUCT_BEVERAGES
df_bigbasket['Platform'] = CONST_PLATFORM_BIGBASKETdf_bigbasket.columnsIndex(['p_desc', 'mrp', 'sp', 'dis_val', 'store_availability', 'rating_info',
'Category', 'Platform'],
dtype='object')df_bigbasket.columns = df_bigbasket.columns = ['ProductName', 'ActualPrice', 'SpecialPrice', 'Discount','IsAvailable', 'Rating', 'Category', 'Platform']df_bigbasket.dtypesProductName object
ActualPrice float64
SpecialPrice float64
Discount float64
IsAvailable bool
Rating object
Category object
Platform object
dtype: objectdf_bigbasket[df_bigbasket['Rating'] != CONST_NOT_APPLICABLE].head()
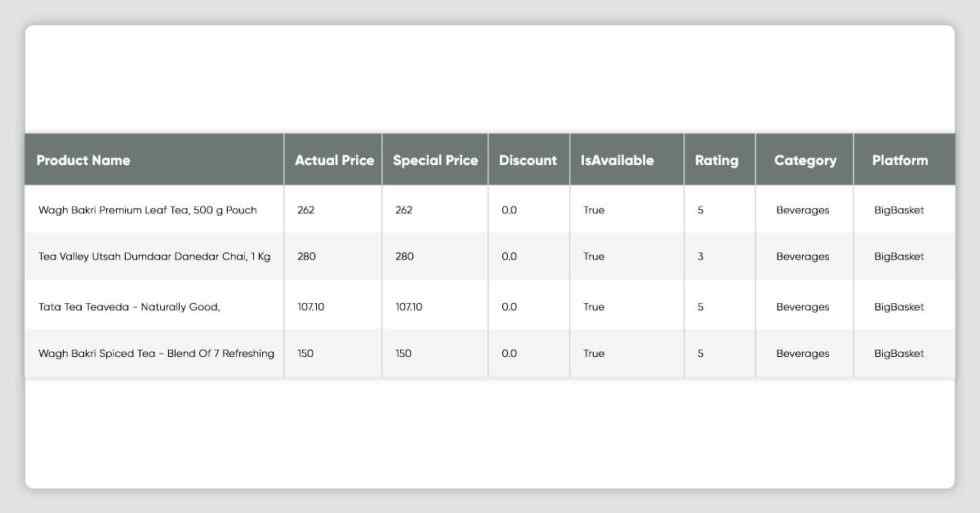
df_dmart = pd.concat(map(pd.read_csv, glob.glob(os.path.join('', "outputs/dmart*.csv"))))
df_dmart.head()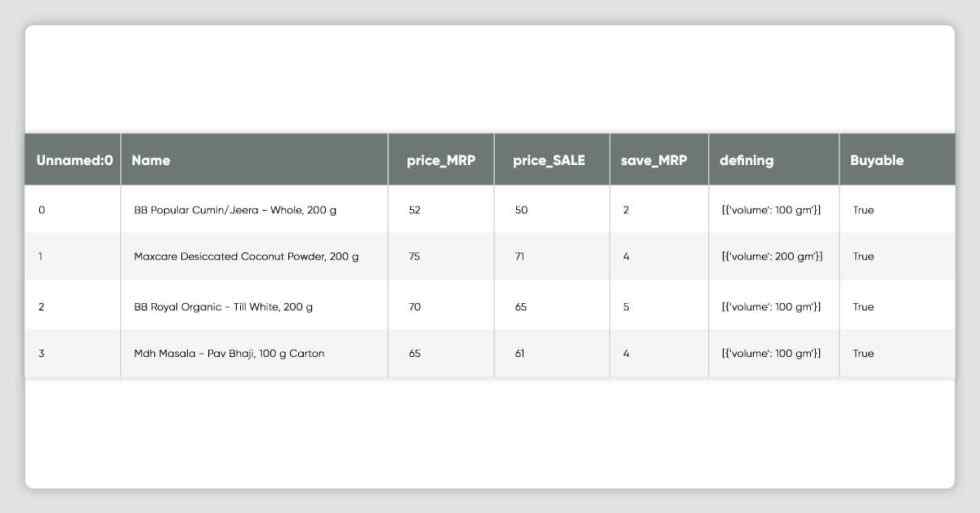
df_dmart.shape(407, 7)df_dmart.drop('Unnamed: 0', axis=1,inplace=True)df_dmart.drop('defining', axis=1,inplace=True)df_dmart['Category'] = CONST_PRODUCT_BEVERAGES
df_dmart['Rating'] = CONST_NOT_APPLICABLE
df_dmart['Platform'] = CONST_PLATFORM_DMARTdf_dmart.columnsIndex(['name', 'price_MRP', 'price_SALE', 'save_price', 'buyable', 'Category',
'Rating', 'Platform'],
dtype='object')df_dmart.columns = df_dmart.columns = ['ProductName', 'ActualPrice', 'SpecialPrice', 'Discount','IsAvailable', 'Category', 'Rating', 'Platform']df_dmart.head()
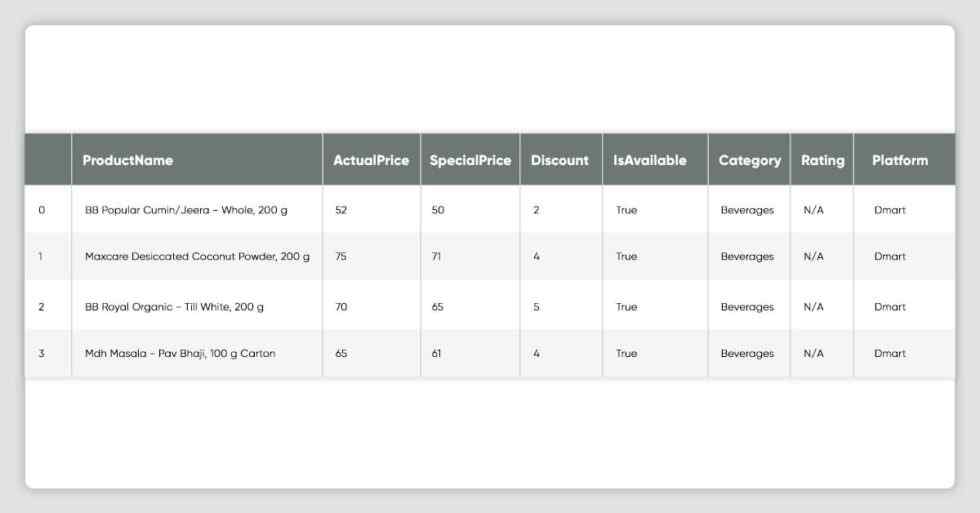
df_flipkart = pd.concat(map(pd.read_csv, glob.glob(os.path.join('', "outputs/flipkart*.csv"))))
df_flipkart.head()'ActualPrice', 'SpecialPrice', 'Discount','IsAvailable', 'Category', 'Rating', 'Platform']df_dmart.head()
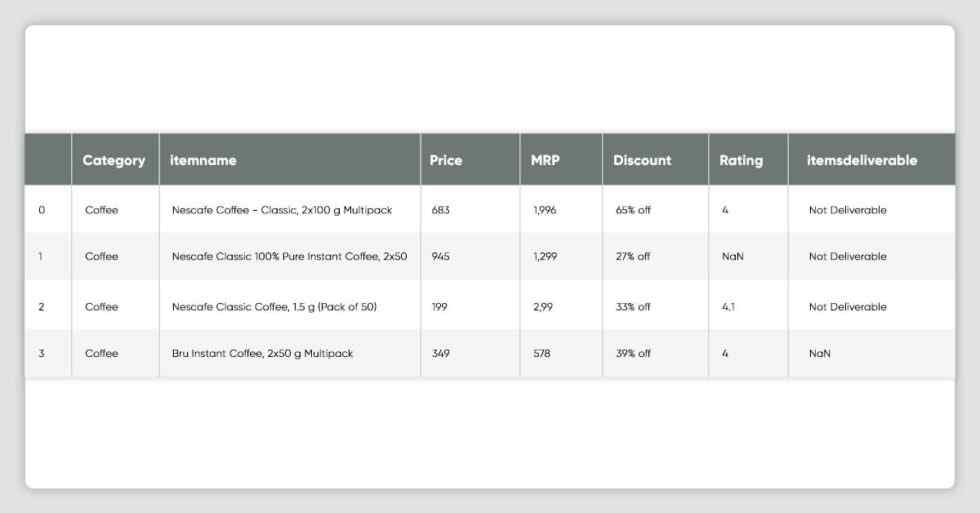
df_flipkart.shape(42006, 7)#df_flipkart[df_flipkart.duplicated(['itemname'])]
df_flipkart.drop_duplicates(subset ="itemname", keep = 'first', inplace = True)df_flipkart['Platform'] = CONST_PLATFORM_FLIPKARTdf_flipkart['itemsdeliverable'].unique()array(['Not Deliverable', nan, 'Temporarily Unavailable',
'itemsdeliverable'], dtype=object)df_flipkart.loc[df_flipkart['itemsdeliverable'] != 'itemsdeliverable', 'itemsdeliverable'] = False
df_flipkart.loc[df_flipkart['itemsdeliverable'] == 'itemsdeliverable', 'itemsdeliverable'] = Truedf_flipkart['itemsdeliverable'].unique()array([False, True], dtype=object)df_flipkart[df_flipkart['itemsdeliverable']== True].shape(1, 8)df_flipkart.columnsIndex(['Category', 'itemname', 'price(₹)', 'MRP(₹)', 'discount', 'rating',
'itemsdeliverable', 'Platform'],
dtype='object')df_flipkart.columns = ['Category','ProductName', 'SpecialPrice', 'ActualPrice','Discount', 'Rating', 'IsAvailable', 'Platform']df_flipkart['ActualPrice'] = df_flipkart['ActualPrice'].replace('₹', '', regex=True).replace(',', '', regex=True)df_flipkart.drop(df_flipkart[df_flipkart['Category'] == 'Category'].index, inplace = True)df_flipkart.head()
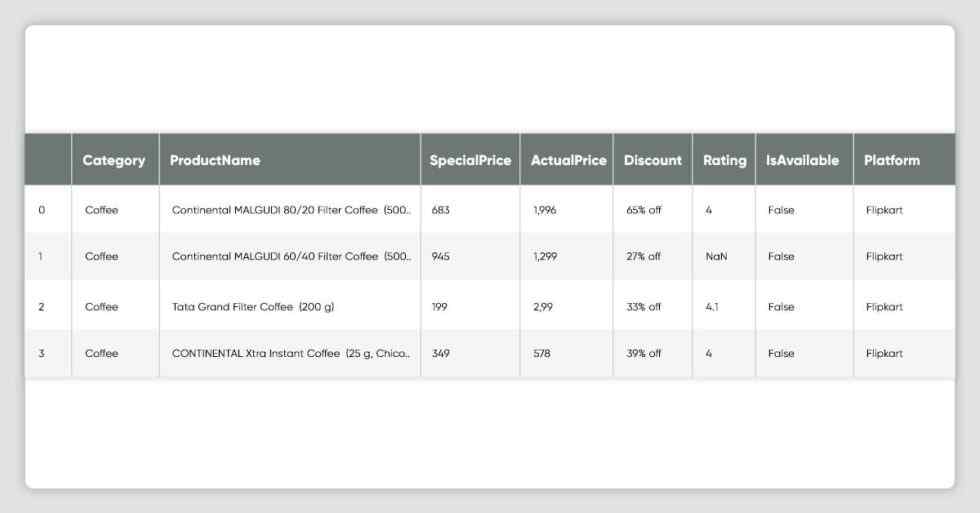
(C) Data Integration
df_all_platforms = pd.concat([df_amazon, df_bigbasket, df_dmart, df_flipkart], axis=0)df_all_platforms.columnsIndex(['ProductName', 'ActualPrice', 'Rating', 'Category', 'SpecialPrice',
'Discount', 'IsAvailable', 'Platform'],
dtype='object')df_all_platforms.dtypesProductName object
ActualPrice object
Rating object
Category object
SpecialPrice object
Discount object
IsAvailable object
Platform object
dtype: objectdf_all_platforms.drop_duplicates(subset ="ProductName", keep = 'first', inplace = True)df_all_platforms['ProductName'] = df_all_platforms['ProductName'].str.lower()df_all_platforms[['ActualPrice']] = df_all_platforms[['ActualPrice']].astype(np.float)df_all_platforms['SpecialPrice'] = df_all_platforms['SpecialPrice'].replace(',', '', regex=True)
df_all_platforms[['SpecialPrice']] = df_all_platforms[['SpecialPrice']].astype(np.float)df_all_platforms['Rating'].fillna(0, inplace=True)df_all_platforms['Rating'] = df_all_platforms['Rating'].replace(CONST_NOT_APPLICABLE , 0, regex=True)df_all_platforms[['Rating']] = df_all_platforms[['Rating']].astype(np.float)df_all_platforms['Discount'] = df_all_platforms['Discount'].replace('%', '', regex=True).replace('off', '', regex=True)df_all_platforms[['Discount']] = df_all_platforms[['Discount']].astype(np.float)df_all_platforms.dtypesProductName object
ActualPrice float64
Rating float64
Category object
SpecialPrice float64
Discount float64
IsAvailable object
Platform object
dtype: objectdf_all_platforms.to_csv('outputs/df_all_platforms.csv', index=False)df_all_platforms[df_all_platforms['Platform'] == CONST_PLATFORM_AMAZON ].head()
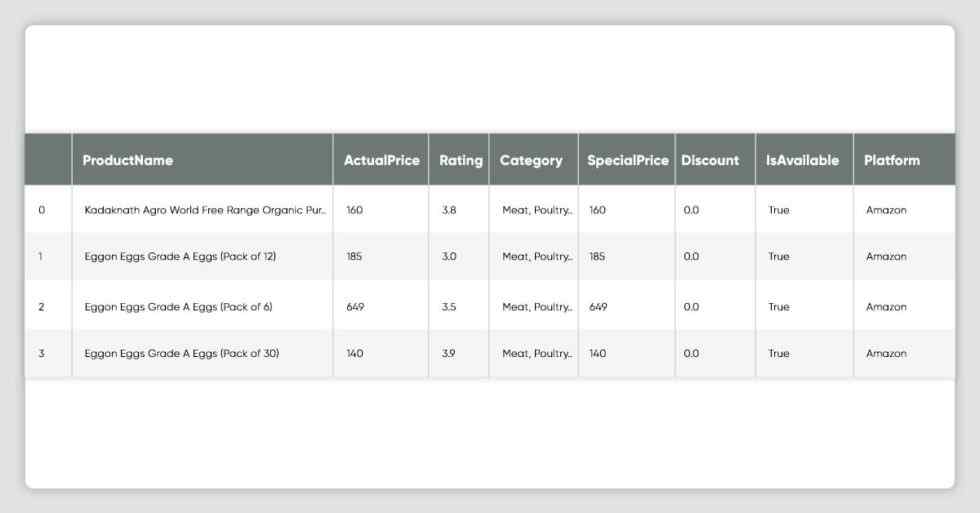
df_all_platforms[df_all_platforms['Platform'] == CONST_PLATFORM_BIGBASKET ].head()
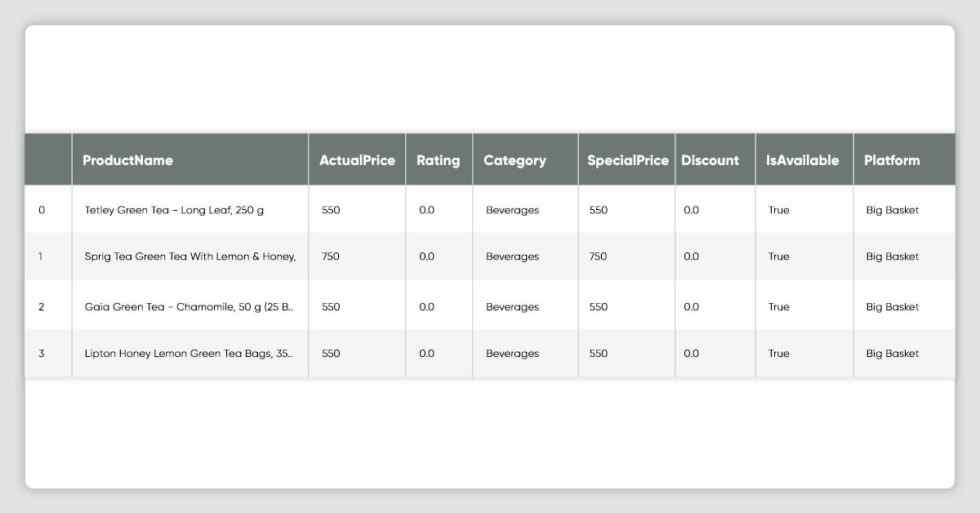
df_all_platforms[df_all_platforms['Platform'] == CONST_PLATFORM_DMART ].head()
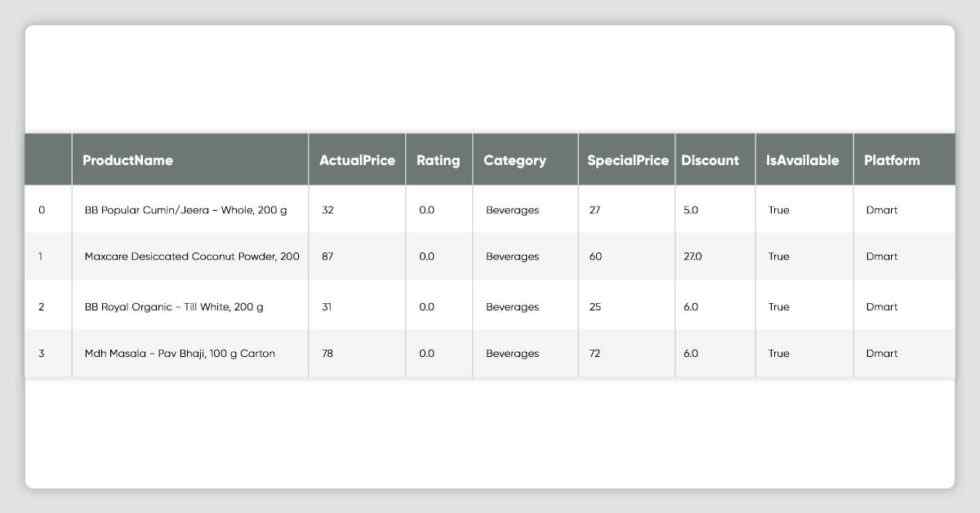
df_all_platforms[df_all_platforms['Platform'] == CONST_PLATFORM_FLIPKART ].head()
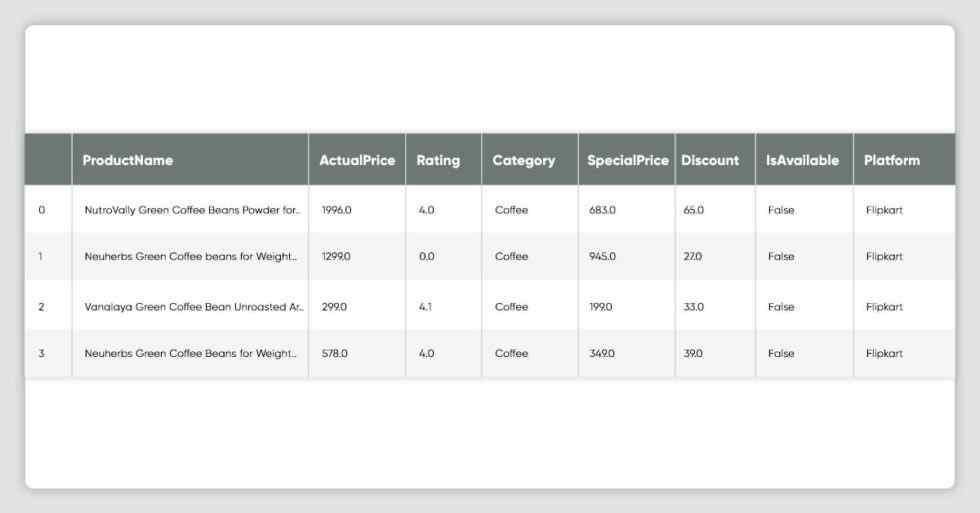
(D) Exploratory Data Analysis and Recommendation
df_all_platforms[(df_all_platforms.duplicated(['ProductName'])) & (df_all_platforms['Platform'] == CONST_PLATFORM_FLIPKART)]
df_all_platforms[(df_all_platforms.duplicated(['ProductName'])) & (df_all_platforms['Platform'] == CONST_PLATFORM_AMAZON)]
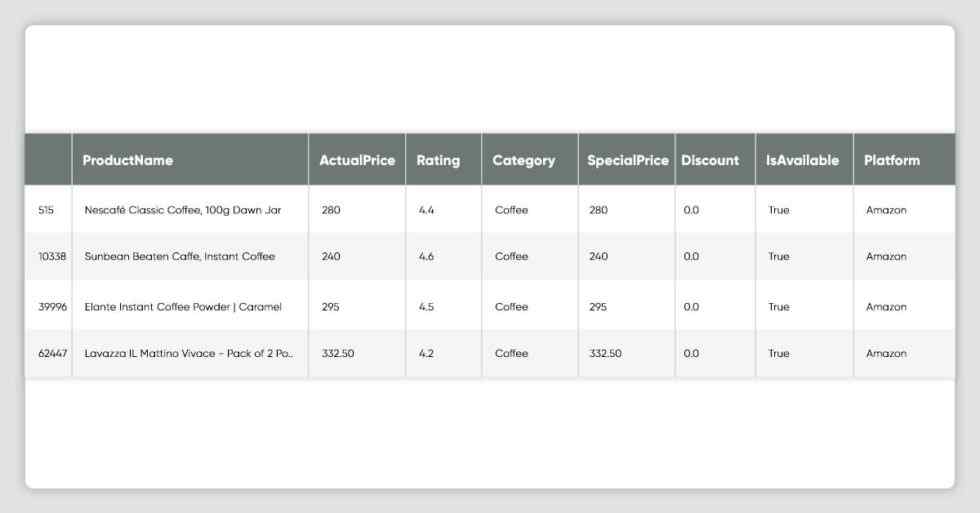
df_all_platforms.shape(2563, 8)df_all_platforms.info()
Int64Index: 2563 entries, 0 to 42002
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ProductName 2562 non-null object
1 ActualPrice 2463 non-null float64
2 Rating 2563 non-null float64
3 Category 2563 non-null object
4 SpecialPrice 2563 non-null float64
5 Discount 2449 non-null float64
6 IsAvailable 2563 non-null object
7 Platform 2563 non-null object
dtypes: float64(4), object(4)
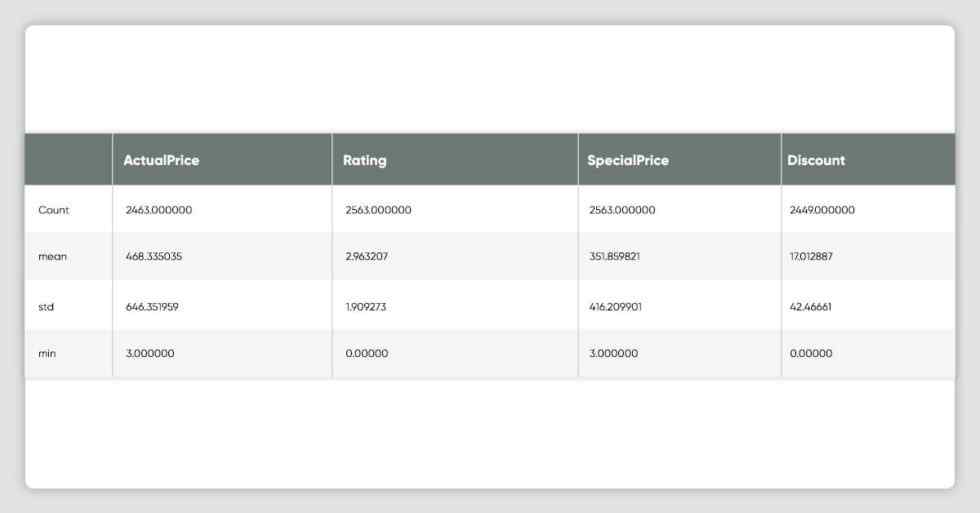
memory usage: 180.2+ KBdf_all_platforms.describe()
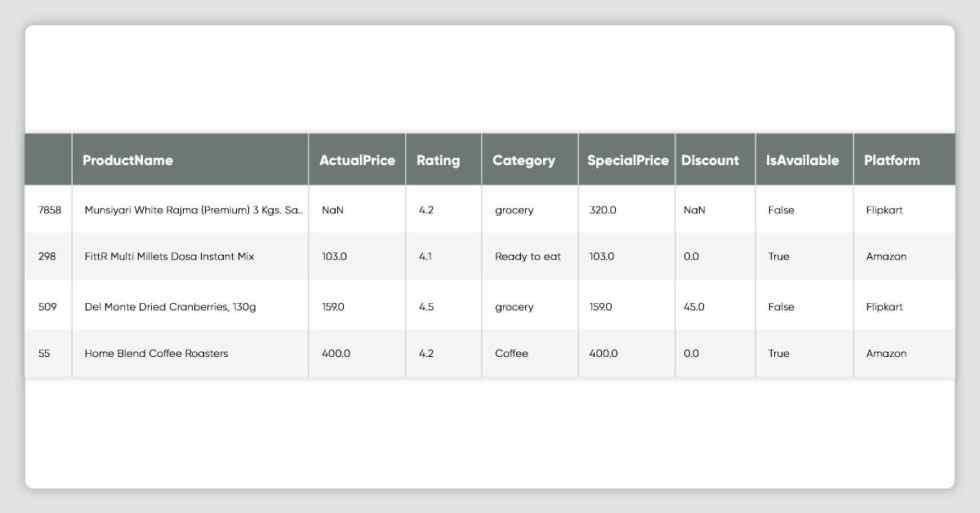
df_all_platforms.sample(10)
sns.jointplot(x="ActualPrice", y="SpecialPrice",kind="reg", data=df_all_platforms)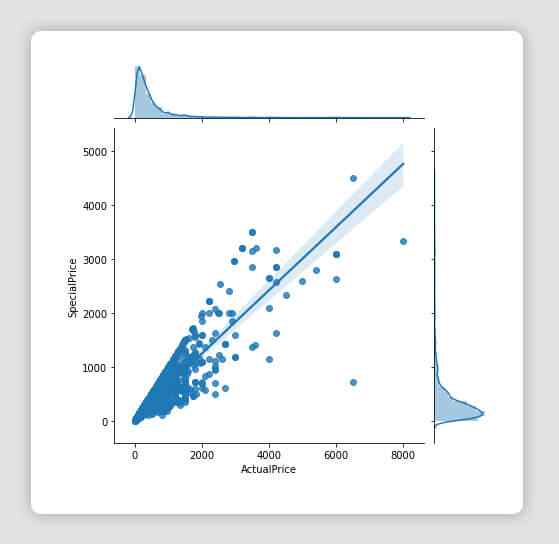
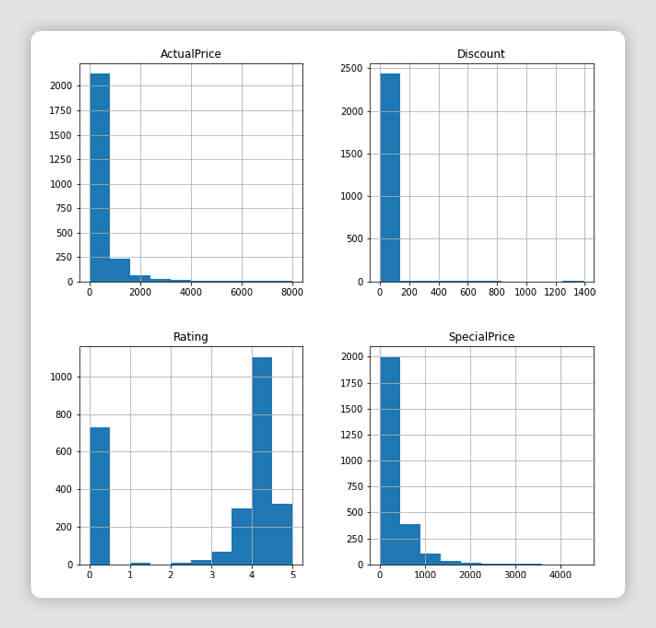
# checking the frequency distribution
df_all_platforms.hist(figsize=(10,10))array([[,
],
[,
]],
dtype=object)
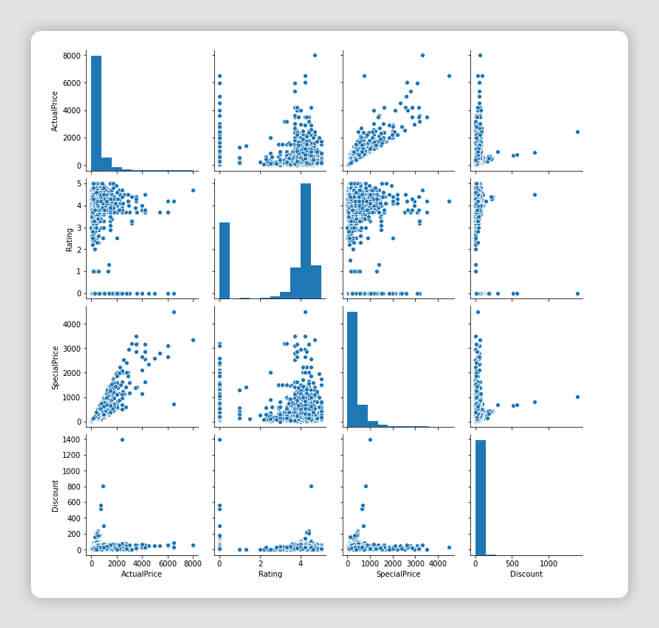
# For each pair of features (columns) in the dataset, we can visualize the scatter plot for each pair
# along with the feature’s histogram along the diagonal
sns.pairplot(df_all_platforms[['ActualPrice','Rating','SpecialPrice','Discount']])
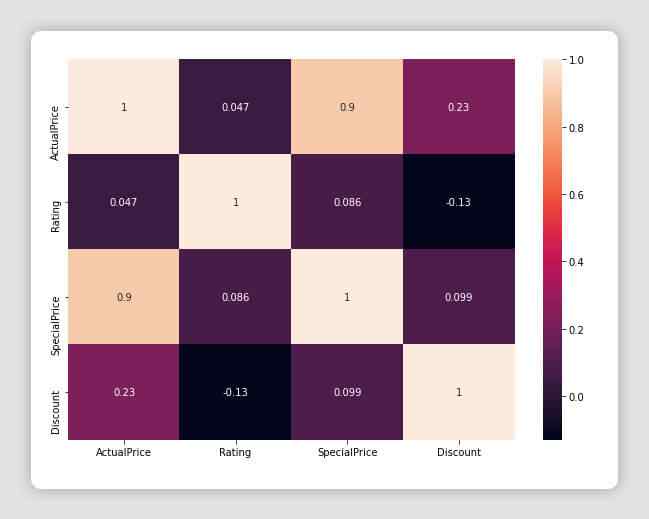
corr = df_all_platforms.corr()
fig = plt.figure(figsize=(10,7))
sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, annot=True)
fig = plt.figure(figsize=(10,7))
sns.set()
ax = sns.countplot(x="Platform", data=df_all_platforms)
df_all_platforms.isna().any()ProductName True
ActualPrice True
Rating False
Category False
SpecialPrice False
Discount True
IsAvailable False
Platform False
dtype: booldf_all_platforms.isna().sum()ProductName 1
ActualPrice 100
Rating 0
Category 0
SpecialPrice 0
Discount 114
IsAvailable 0
Platform 0
dtype: int64df_all_platforms.isna().sum().sum()215fig = plt.figure(figsize=(20,12))
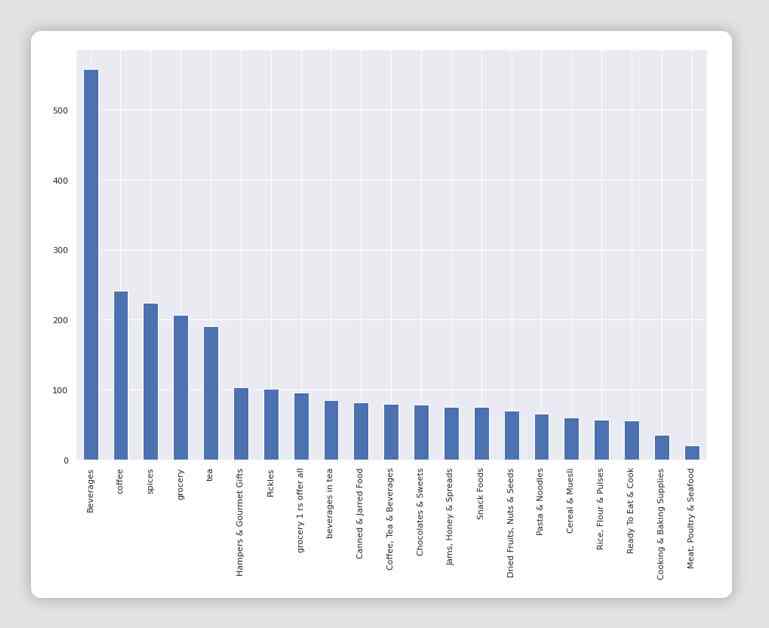
ax = sns.countplot(x="Category", data=df_all_platforms)
ax.set_xticklabels(ax.get_xticklabels(), rotation=40, ha="right")
plt.tight_layout()
plt.show()
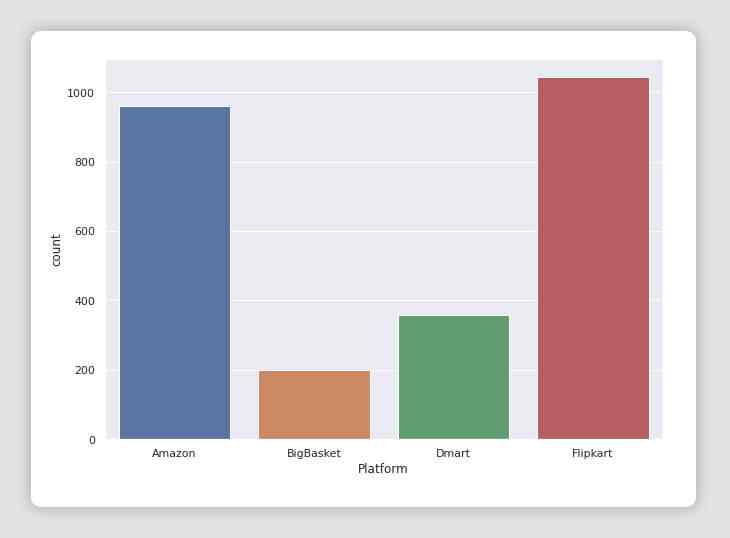
fig = plt.figure(figsize=(15,10))
df_all_platforms['Category'].value_counts().T.plot(kind='bar', stacked=True)
def search(sender):
''' recomending user based on special price and ratings. '''
search_item = sender.value.lower()
df_filtered = df_all_platforms[df_all_platforms['ProductName'].astype(str)\
.str.contains(search_item)].sort_values(by=['SpecialPrice'], ascending=[True])\
.groupby(by=['Platform']).first()
df = df_filtered.sort_values(by=['Rating'], ascending=[False]).copy()
df.reset_index(inplace=True)
df_top_product = df.iloc[0]
msg = str.format('Recommended Platform : {0}', df_top_product.Platform)
print(tabulate([[msg]], tablefmt='fancy_grid'))
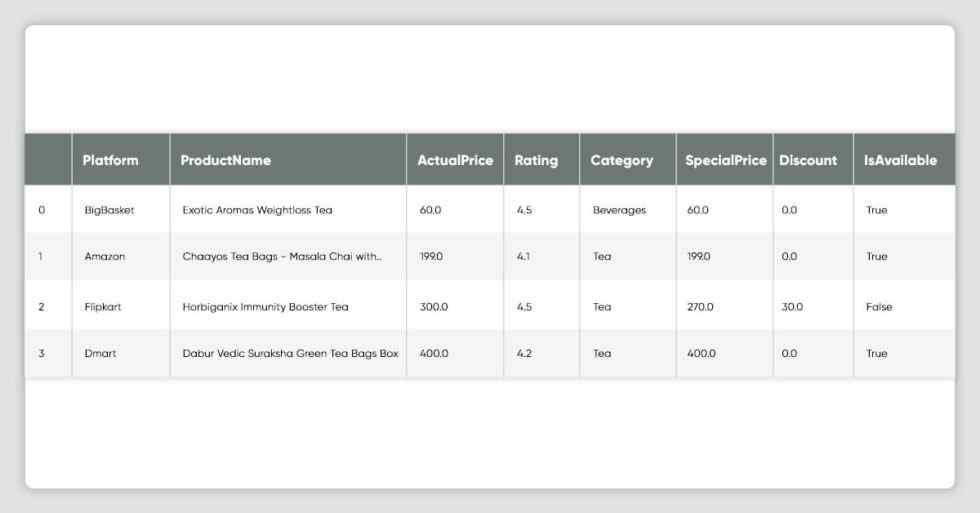
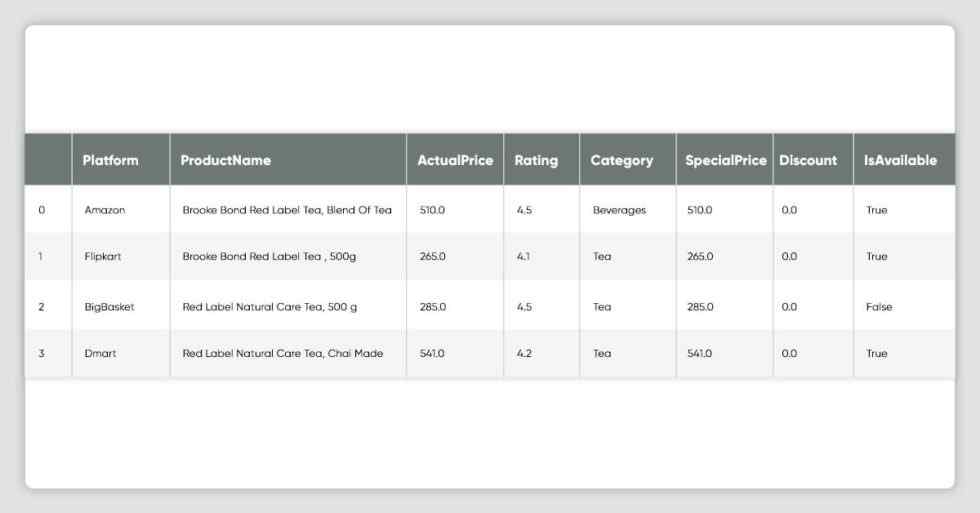
display(df)
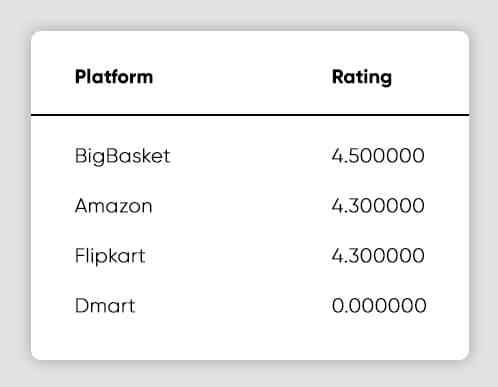
display(df[['Platform','Rating']].head(4).style.hide_index().highlight_max(color='lightgreen'))
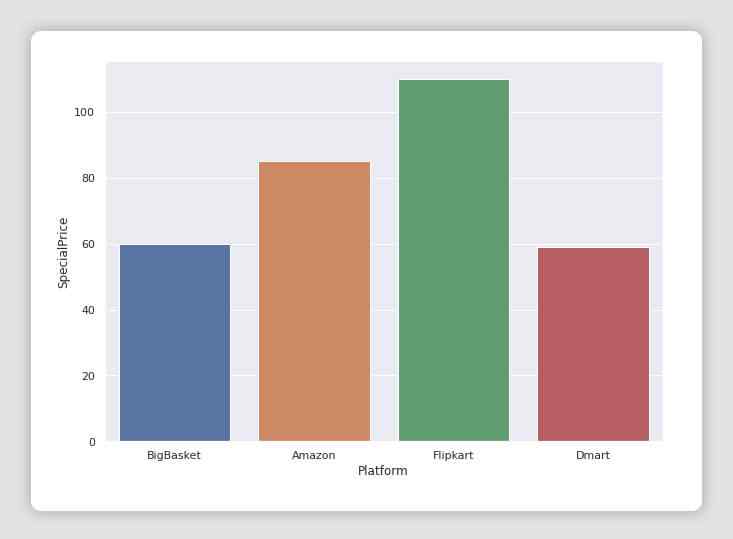
fig = plt.figure(figsize=(10,7))
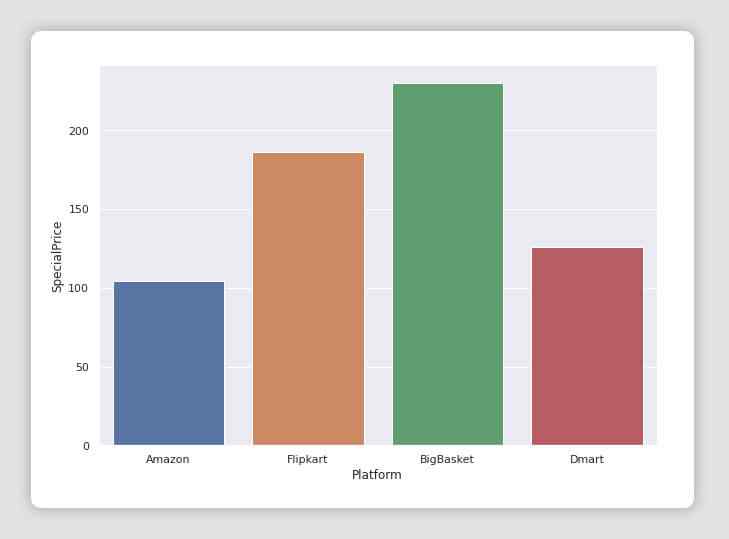
ax = sns.barplot(x="Platform", y="SpecialPrice", data=df, capsize=.2)# recommending basedon price and ratings
text = widgets.Text()
print(tabulate([['Type the product name in below box and press enter to search.']], tablefmt='grid'))
display(text)
text.on_submit(search)+---------------------------------------------------------------+
| Type the product name in below box and press enter to search. |
+---------------------------------------------------------------+
Text(value='')
╒══════════════════════════════════╕
│ Recommended Platform : BigBasket │
╘══════════════════════════════════╛
# recommended basedon price and ratings
text = widgets.Text()
print(tabulate([['Type the product name in below box and press enter to search.']], tablefmt='grid'))
display(text)
text.on_submit(search)+---------------------------------------------------------------+
| Type the product name in below box and press enter to search. |
+---------------------------------------------------------------+
Text(value='')
╒═══════════════════════════════╕
│ Recommended Platform : Amazon │
╘═══════════════════════════════╛
print('END OF NOTEBOOK')END OF NOTEBOOK
Are you looking for Web Scraping Service?
Contact X-Byte Enterprise Crawling
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯
Alpesh Khunt, CEO and Founder of X-Byte Enterprise Crawling created data scraping company in 2012 to boost business growth using real-time data. With a vision for scalable solutions, he developed a trusted web scraping platform that empowers businesses with accurate insights for smarter decision-making.




Facebook
Twitter
Instagram
YouTube







