

Beautiful Soup was used to collect statistics on the top 250 TV series on IMDb.
The Internet Movie Database (IMDb) is the world’s largest entertainment database. It offers information about movies, TV shows, video games, home videos, and other forms of entertainment. Whenever individuals wish to share their reviews regarding a film or show’s performance, they choose IMDB as their evaluation platform. As a result, it has evolved into a platform for individuals to learn about the performance of their favorite film or television show.
Data scientists have scraped data from IMDB to examine how different movies or TV series perform because it is widely considered an excellent resource for varied entertainment material. It is necessary to study data from IMDb after discovering the ability to extract IMDB information from the huge library of entertainment content on the site.
Data Scraping and Information Collection
Web Scraping can be done using BeautifulSoup using Python in X-Byte Enterprise Crawling. Here’s how you scrape data from websites with Beautiful Soup. X-Byte Enterprise Crawling is a platform that enables programmers to run code in cells. As a result, individuals will find it simple to execute their code in stages till they reach the final product.
from bs4 import BeautifulSoup from requests import get
You can also use the requests package’s get method to acquire the URLs of the IMDb sites that you want to scrape. It is recommended that individuals install the beautiful soup package using the code below before loading the beautiful soup package:
! pip install beautifulsoup4
The next step was to determine which variables were relevant and gather data on them after loading the correct packages and installing gorgeous soup using the coding terminal or an X-Byte Enterprise Crawling cell. The code you will need to use to collect data on the top 250 shows on IMDb is as follows:
from bs4 import BeautifulSoup
from requests import get
import pandas as pd
import requests
import re
# url with the link to the top 250 highest rated TV shows list
url = 'https://www.imdb.com/chart/toptv'
response = get(url)
tv_soup = BeautifulSoup(response.text, 'html.parser')
# collecting info about all the tv shows from the website
containers = tv_soup.find_all('td', class_='titleColumn')
# collecting info about the tv shows' ratings
containers_rating = tv_soup.find_all('td', class_ = "ratingColumn imdbRating")
# listing out the ratings of the TV shows
rating_list = []
for i in range(len(containers_rating)):
rating = containers_rating[i].strong["title"]
rating = rating[:3]
rating_list.append(rating)
# listing out the encoded title of all the tv shows
tv_list = []
for i in range(0,len(containers)):
title = containers[i].a['href']
title = title.split("/")[2]
tv_list.append(title)
# creating a list that extracts information about each tv such as
# title, rating, total_votes, description, release year, its link and its encoded title
comprehensive_list = []
for tv in tv_list:
response = get('https://www.imdb.com/title/' + tv + "/")
tv_soup = BeautifulSoup(response.text, 'html.parser')
title_verbose = tv_soup.find('title').string
releaseYear = re.findall(r'[0-9][0-9][0-9][0-9]', title_verbose)
tv_soup = BeautifulSoup(response.text, 'html.parser')
#tv_title = tv_soup.find('title').string
#rating = tv_soup.find("span", class_ = "AggregateRatingButton__RatingScore-sc-1ll29m0-1 iTLWoV").string
rating_count = tv_soup.find("div", class_ ="sc-7ab21ed2-3 dPVcnq").string
tv_title = tv_soup.find("h1", {"data-testid": "hero-title-block__title"}).string
description = tv_soup.find("span", {"data-testid": "plot-xl"}).string
link = 'https://www.imdb.com/title/' + tv
encoded_title = tv
genres = tv_soup.find_all('a', class_ = "GenresAndPlot__GenreChip-sc-cum89p-3 LKJMs ipc-chip ipc-chip--on-baseAlt")
genre = ""
for g in genres:
genre += g.text + ", "
genre = genre.strip(", ")
comprehensive_list.append([tv_title, rating_count, description, releaseYear[0], link, encoded_title, genre])
# converting comprehensive_list into a data frame
tv_best = pd.DataFrame(comprehensive_list, columns = ["title","total_votes", "show_desc", "year", "link", "encoded_title", "genre"])
# saving the rating list to a column
tv_best["rating"] = rating_list
tv_best["rating"] = tv_best["rating"].astype(float)
tv_best = tv_best[["title","rating","total_votes", "show_desc", "year", "link", "genre","encoded_title"]]
# converting K to 000 for total votes and M to 000000 for total votes
tv_best["total_votes"] = tv_best["total_votes"].str.replace("K", "000")
tv_best["total_votes"] = tv_best["total_votes"].str.replace("M", "000000")
# reseting index of data frame
tv_best = tv_best.reset_index(drop = True)
# using a for loop to return a better result for the total votes column as some elements contain .
for i in range(len(tv_best)):
if "." in tv_best.loc[i, "total_votes"]:
tv_best.loc[i,"total_votes"] = tv_best.loc[i, "total_votes"][:-1]
# replacing . with an empty string so total votes can be converted into integer
tv_best["total_votes"] = tv_best["total_votes"].str.replace(".", "")
# transforming certain columns into integers
tv_best["rating"] = pd.to_numeric(tv_best["rating"], downcast="float")
tv_best["total_votes"] = tv_best["total_votes"].astype(int)
tv_best["year"] = tv_best["year"].astype(int)
# Saving the data set
tv_best.to_csv("IMDb_top_250.csv", index = False)
The top 10 rows of the data set produced using the code above are shown below:

After extracting IMDB’s top 250 series, the next stage was to collect data on each TV show’s episodes and combine them into one massive data collection.

As previously said, a data collection similar to the one above was constructed for each TV show. The information was then integrated to build a massive database of IMDb TV program episodes. The code cells that you will use to create the data set may be found here. It’s in the Collecting episode data section.
The top 1000 episodes on IMDb were another key data set to build. This data collection, would be critical in determining how prolific the top 250 shows are in terms of creating high-quality episodes. The code for gathering the top 1000 episodes on IMDb may be found here. The top five rows of IMDb’s top 1000 episodes are shown here.

Visualizations
The following are many images that depict the performance of the TV shows. The visualizations were built by exporting the data sets to Tableau and using the business intelligence platform’s capabilities to construct dashboards that showed the information clearly.
Top Ten Shows Based on Ratings
The top ten shows in terms of ratings are summarized in the first image on the list. Two graphs are included in the picture. The chart on the left shows the top 10 programs based on their average episode ratings, while the chart on the right shows the top 10 shows based on their IMDb page ratings. It’s worth noting that the lists of TV series on the two charts are not identical.
On the left, the average ratings of all episodes of each TV program are used, while on the right, their IMDb ratings are used.

Top Ten Shows Based on Votes
The picture focuses on the TV series in terms of the number of votes they may receive. It also includes two graphs. The top 10 programs on the left are ranked by average votes per episode, while the top 10 shows on the right are ranked by the number of individuals who have rated the episodes on their IMDb sites.
A similar remark to the one above may be found below. Because different measures are used to assess success, there is a mismatch in the list of TV series on both charts. The one on the left focuses on the average votes across all episodes of each TV show, whereas the one on the right focuses on the average votes across all episodes of each TV program.

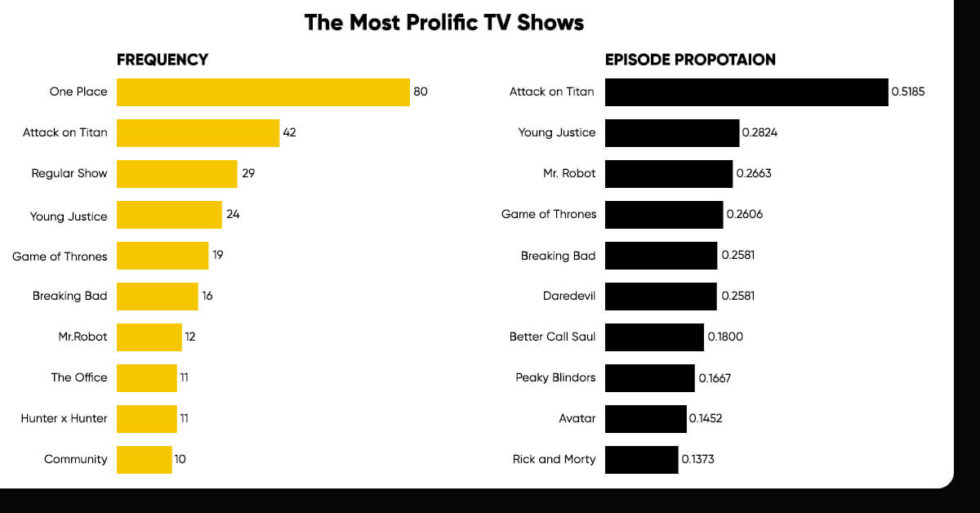
The Most Successful TV Shows
Here’s a breakdown of the most popular programs on IMDb. The explanation for these two graphs derives from the fact that some TV series are more likely to generate exceptional episodes with IMDb ratings close to ten stars. As a result, it was fascinating to see which TV series contributed the most to IMDb’s top episodes. As a result, you can compile a list of the top 1000 episodes on IMDb and examined them.
The chart on the left is based on counting the TV series that contributed the most to IMDb’s list of the top TV shows, but the chart on the right is based on the proportion of episodes of that show that were seen.
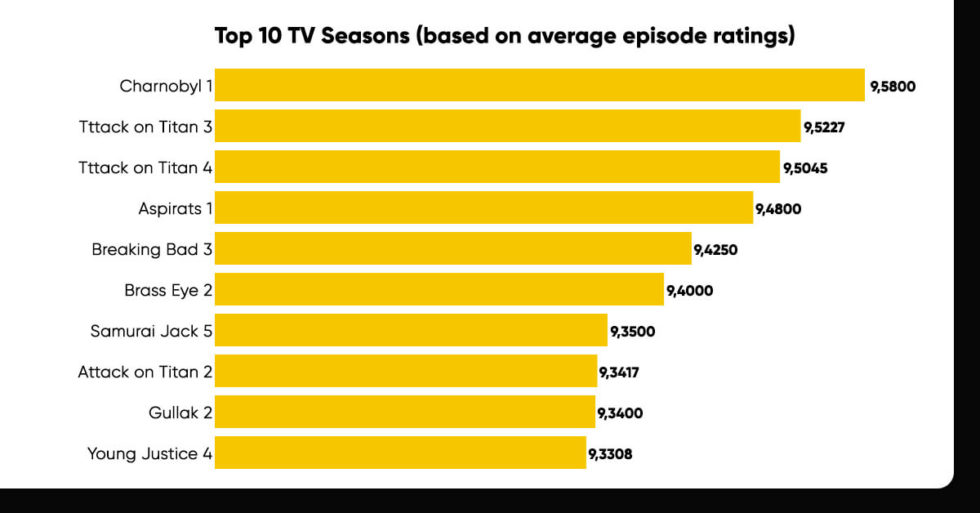
Top Ten Television Seasons
There is just one chart in this picture. The goal of this picture was to rank the top 10 TV program seasons based on their average episode ratings. Three of Attack on Titan’s four seasons are listed in the top 10 seasons on IMDb, making it a major show on this list.
If you are looking for any web scraping services such as scraping IMDB data, you can contact X-Byte Enterprise Crawling!
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯











